
Voice AI applications are changing how businesses handle customer interactions and how users navigate digital interfaces. These systems process spoken requests, understand natural language, and respond with generated audio in real time.
Building a voice AI application requires understanding speech processing, language models, and real-time communication infrastructure. You need systems that can detect when users finish speaking, convert audio to text, generate appropriate responses, and convert those responses back to audio.
This guide covers the essential components, architecture patterns, and implementation approaches for building voice AI applications. From customer service bots to internal productivity tools, we’ll examine the core technologies and frameworks that enable these conversational systems.
What You’ll Learn:
- Core components of voice AI application architecture
- Turn detection mechanisms and media pipeline strategies
- Cascade vs. multimodal processing approaches
- Infrastructure requirements for web, mobile, and telephony integration
- Real-world implementation frameworks and tools
Components of a Voice AI Application
In a voice AI application, users interact with an AI agent using their voice. This interaction is supported by two main components:
- An agent application
- A transport mechanism
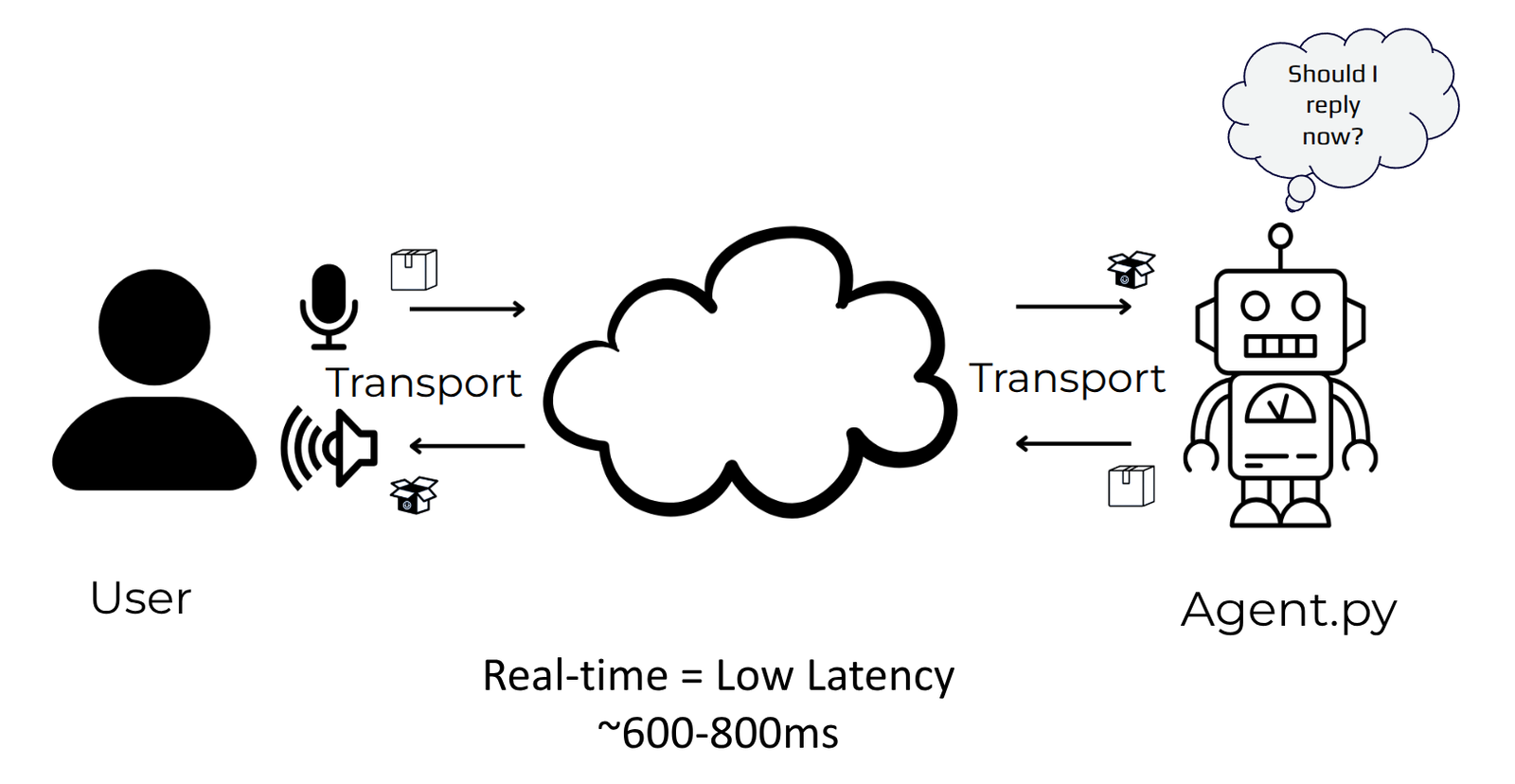
The agent application continuously listens for users’ requests, which arrive as audio streams, until it determines the user has finished speaking. It then processes the request and generates a response that it sends back to the user as an audio stream.
The transport mechanism handles the delivery of audio streams between the user’s device and the agent application in both directions.
We will delve deeper into these topics in subsequent sections. For now, it’s crucial to remember that all transport and processing occur in real-time, with sub-second latency, typically between 600 and 800 milliseconds, which is the current industry standard.
Building an AI Voice Agent
The agent application is a server-side application that exposes an entry point to establish communication, such as a REST API or WebSocket endpoint. Once established, it listens and processes users’ requests through a series of steps that include:
- Turn Detection
- Media Pipeline
When building such an application, the common practice is to use an agent framework, such as Pipecat, LiveKit Agents or Twilio ConversationRelay. These frameworks not only simplify the implementation of the above steps, but also make integration with the selected transport mechanism easier.
Turn Detection Mechanism
Turn Detection enables the application to identify when a user has finished speaking, prompting the system to formulate a response. Conversely, it also allows the agent to recognize if a user has interrupted an ongoing response, facilitating an appropriate reaction.
There are multiple approaches for Turn Detection:
- Voice activity detection (VAD): This approach consists of running an AI model that analyzes audio signals. This allows us to set thresholds of silence after which the bot should reply.
- Push to Talk: Here, the user interface of the client-side application provides a cue that the user can activate -like an UI element that can be clicked, or a keyboard shortcut- to indicate the agent application when it should start or stop talking.
- Endpoint Markers: In this approach, the application logic defines specific keywords that will mark the end of a user’s turn. This is similar to how radio communication works.
- Context-aware Turn Detection: This approach combines multiple methods to create an agent application that interprets various human cues, determining when a user has finished speaking. One example is a Voice Activity Detection (VAD) working with a Small Language Model to analyze transcriptions, looking for filler words and punctuation to identify if the user has truly stopped talking or merely paused to think.
Media Pipeline
After the agent determines it’s time to talk, the processing of the input begins. As part of this processing, the agent application not only understands what is being requested, but also retrieves additional context and leverages both external and internal tools that can be used to fulfill the user’s requests.
There are two main approaches for this media pipeline processing:
- Cascade
- Multimodal
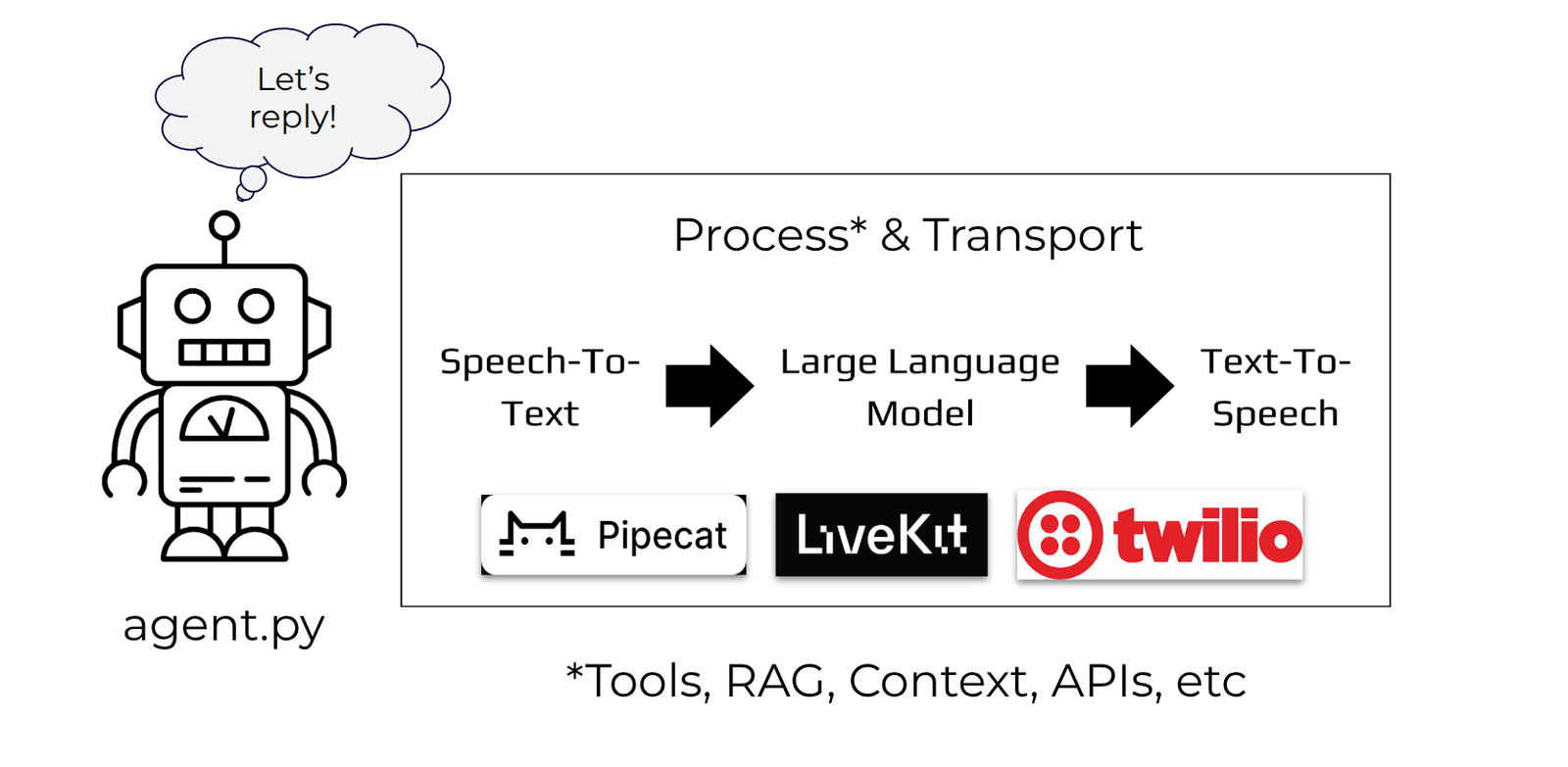
Cascade
The cascade approach transports user requests through a series of AI models. Each model’s output serves as the subsequent model’s input, with the final model in the sequence generating the response.
An agent application needs at least three types of models:
- Speech to Text (STT) Model: Converts the user’s audio input to text.
- Large Language Model (LLM): Generates a text response or points out the tool required to generate it.
- Text to Speech (TTS) Model: Converts the text response into audio.
These models can run alongside the application or be available through remote endpoints.
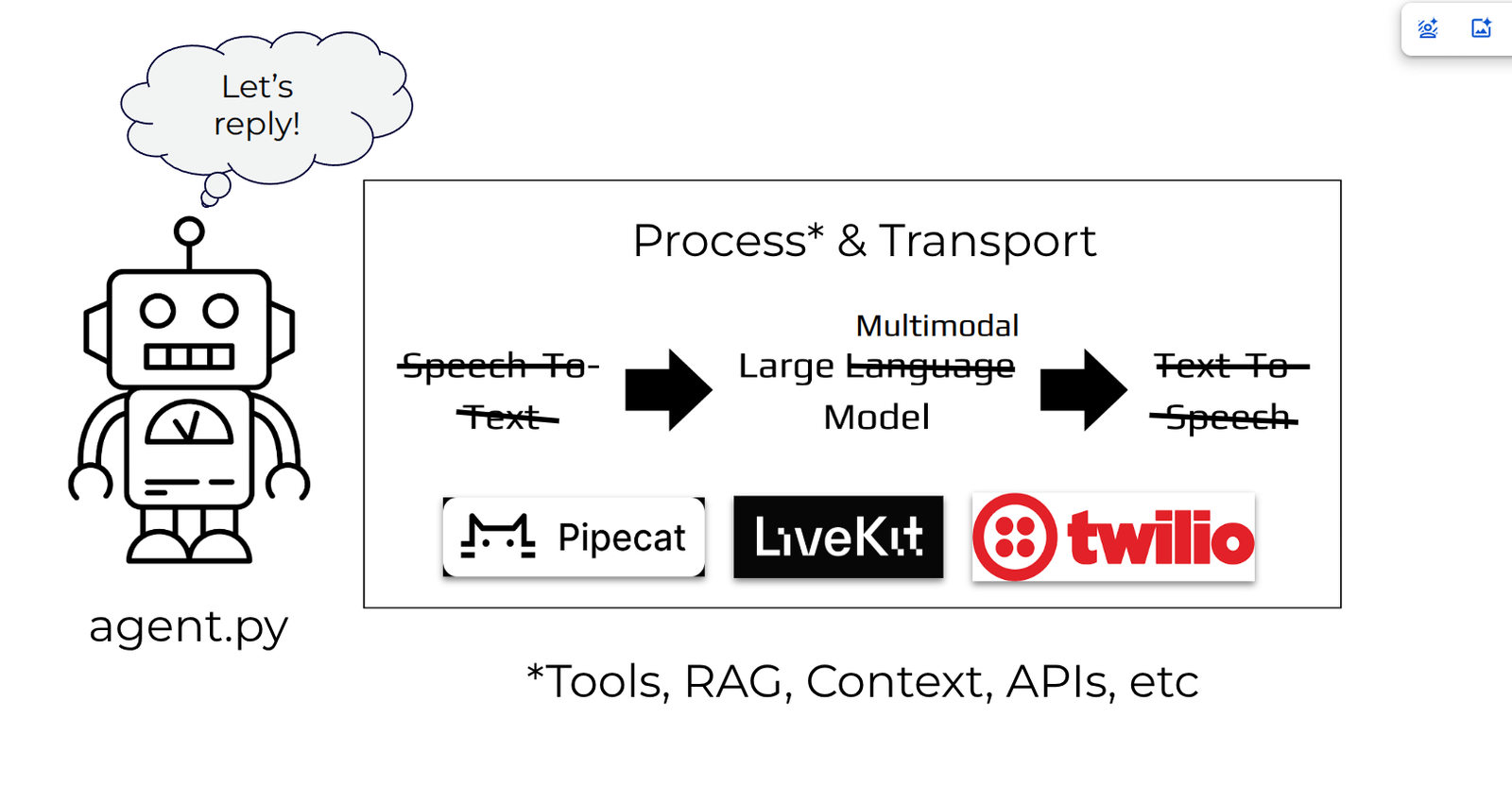
Multimodal
The multimodal approach relies on a single Large Multimodal Model (LMM) to process audio input and generate both text and audio outputs. This method offers simplicity due to fewer components and significantly reduced latency as all processing occurs in one centralized location.
In addition to audio, LMMs are able to process and generate other modalities of inputs and outputs, including videos and images.
However, LMMs are considerably more expensive and often come with increased complexity for managing additional context and available tools. Also, they’re not on par (yet) with the state-of-the-art Large Language Model in terms of advanced reasoning. So, LMMs might not be suitable for all use cases.
Same as with the cascade approach, LMMs can run alongside the application or in a remote endpoint.
Voice AI Application Architecture
With the agent application covered, the next step is to design the architecture of the Voice AI application. To do so, it’s crucial to define the supported interfaces through which users will interact with the agent application.
Such interfaces include:
- Traditional telephony (i.e., inbound/outbound phone calls)
- Web applications
- Native/Desktop applications
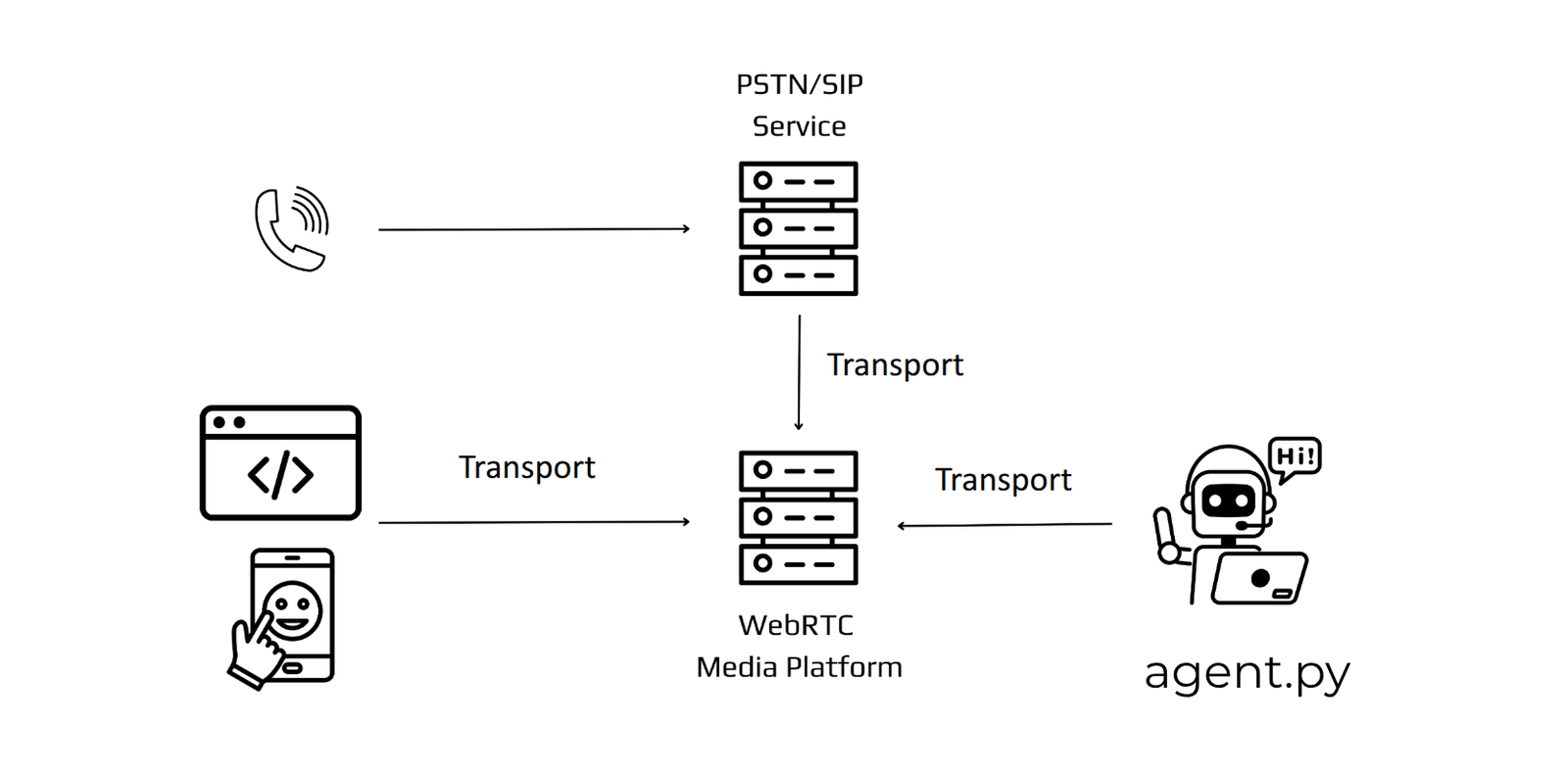
These interfaces define the required infrastructure and appropriate transport mechanisms for the Voice AI application:
- Agent applications connecting to external communication platforms or AI models through fast and reliable connections can use WebSockets.
- Web and native applications running on users’ devices in home or corporate networks work best when delivering media using WebRTC. Connection with agent applications can be done either directly or through a WebRTC platform maintained by you or a specialized provider such as Daily, LiveKit Cloud, or Signalwire.
- Traditional telephony requires an additional piece of infrastructure that serves as a gateway between the Public Switched Telephone Network (PSTN) and the WebRTC platform mentioned above. This gateway can either be managed internally or accessed through specialized providers or services like Twilio or Amazon Connect.
Voice AI Applications Revealed
Understanding the anatomy of a voice AI agent reveals the complex engineering behind these transformative tools. From the initial audio input processed by a turn detection mechanism, through the intelligent decision-making of the media pipeline (whether via a cascade of specialized models or a powerful multimodal approach), to the robust architecture that connects it all, each layer plays a critical role.
Ready to bring your voice AI vision to life? At WebRTC.ventures, we specialize in developing and implementing cutting-edge voice AI applications, leveraging deep expertise in real-time communication and intelligent conversational systems. Whether you’re looking to enhance customer service, streamline internal operations, or create innovative user experiences, our team can help you navigate the complexities and build a robust, scalable voice AI solution. Contact us today!
Further Reading:
- Building a Smart IVR Agent System with LiveKit Voice AI: Say Goodbye to “Press 1 for Sales”
- Reducing Voice Agent Latency with Parallel SLMs and LLMs
- Talking to Yourself Without Looking Crazy: Building a Voicebot with Your Cloned Voice Using Cartesia and LiveKit Agents
- Optimizing Prompts for Real-Time Voice AI










