
Voice assistants powered by real-time AI are increasingly being used to automate phone-based customer interactions. Whether for contact centers, internal help desks, or voice-driven workflows, a reliable architecture needs to support low-latency audio streaming, accurate speech-to-text (STT), intelligent response generation, and real-time speech synthesis.
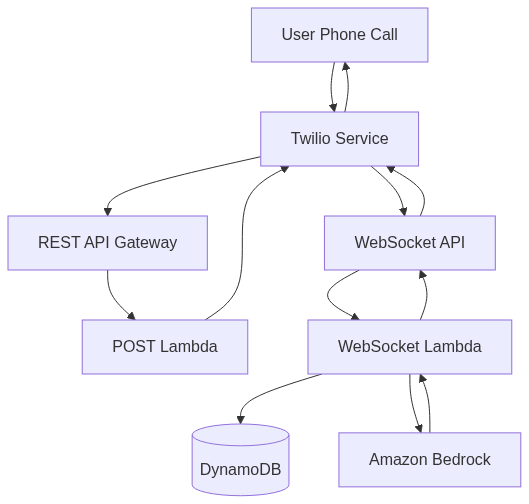
In this post, we walk through how to build a serverless Voice AI assistant that runs entirely on the scalable power of the AWS infrastructure, using Twilio ConversationRelay as the telephony interface. This approach enables real-time, bi-directional audio powered by large language models (LLMs), without the need to manage dedicated servers or media pipelines.
This post builds on our earlier article, “Twilio’s ConversationRelay GA Release Brings Voice AI to the Enterprise Mainstream”, which covered the feature set and capabilities of Twilio’s ConversationRelay platform in its general availability release.
Here we’ll focus on the technical architecture and implementation details, including:
- Generating and returning a TwiML response to activate ConversationRelay over a voice call
- Handling all WebSocket events through an AWS Lambda function
- Maintaining session state in Amazon DynamoDB
- Calling Amazon Bedrock for Generative AI responses
- Streaming AI-generated text back to Twilio for real-time TTS rendering
How does Twilio ConversationRelay work?
ConversationRelay leverages Twilio’s robust communication infrastructure. To set it up, connect your phone number to a configured POST route. This route should return a TwiML noun instructing the platform to activate ConversationRelay and provide a WebSocket endpoint for your application to receive user input.
The platform manages the transcription of user input, sends it to your application via a WebSocket connection, and then converts the application’s response into audio for the end-user. This is achieved through integrations with leading Voice AI services like Deepgram, ElevenLabs, and voice services from Google Cloud and Amazon.
Your application handles two key responsibilities:
- TwiML Noun Construction: This allows for flexible configuration of your voicebot, including supported languages and your preferred Speech-to-Text (STT) and Text-to-Speech (TTS) platforms.
- Business Logic for LLM Response Generation: This involves incorporating the necessary logic to generate responses using your chosen Large Language Model (LLM) inference platform.
Such logic can be provisioned in a serverless manner using AWS API Gateway and AWS Lambda. To simplify replication and management, we will utilize Amazon Serverless Application Model (SAM) for provisioning all necessary resources. The example code is available in the serverless-twilio-cr-aws GitHub repository.
Note that this demo focuses on the core logic and integration of the services, so it lacks the necessary authentication and authorization mechanisms for a production environment. Implementing these mechanisms is beyond the scope of this post.
Prerequisites
Before you begin, ensure you have the following:
- A Twilio account with a purchased phone number
- An AWS account with configured credentials
- The SAM CLI installed and configured
Write the TwiML Lambda Function
Let’s start by setting up the TwiML endpoint. To do so we need to write a Lambda function that returns a TwiML noun with the basic configuration for ConversationRelay.
Such a noun is an XML document. Its root node is Response, and nested within it, under Connect, is a ConversationRelay node. The latter requires two properties: a WebSocket endpoint URL and a welcome message for the assistant.
In the Lambda function, we build the WebSocket URL by concatenating the domain name and stage of the API Gateway serving the WebSocket. We will see how to set these later in this post, for now, let’s assume that they are available in STAGE and DOMAIN_NAME variables in the lambda.
# src/post/app.py
...
def lambda_handler(event, context):
# Get the WebSocket URL from environment variable or construct it
stage = os.environ.get('STAGE', 'prod')
domain = os.environ.get('DOMAIN_NAME')
# Construct WebSocket URL
ws_url = f"wss://{domain}/{stage}"
# Create TwiML response
xml_response = f"""
<?xml version="1.0" encoding="UTF-8"?>
<Response>
<Connect>
<ConversationRelay url="{ws_url}" welcomeGreeting="{WELCOME_GREETING}" />
</Connect>
</Response>
"""
return {
'statusCode': 200,
'headers': {
'Content-Type': 'text/xml'
},
'body': xml_response
}
In our SAM template we create both the Lambda function and the API Gateway resources at once by leveraging the AWS::Serverless::Function resource. To do so, in addition to the function details (name, folder where the code is available, handler, runtime, etc) we also add a PostApi event that exposes the function through a /twiml POST route.
We also add the environment variables we mentioned earlier for the WebSocket API domain name and stage. These reference the WebSocketStage and WebSocketApi resources we will create later.
# template.yaml
...
# REST API with Lambda Integration
PostFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: twilio-cr-twiml-function
CodeUri: src/post/
Handler: app.lambda_handler
Runtime: python3.12
Environment:
Variables:
STAGE: !Ref WebSocketStage
DOMAIN_NAME: !Sub ${WebSocketApi}.execute-api.${AWS::Region}.amazonaws.com
Events:
PostApi:
Type: Api
Properties:
Path: /twiml
Method: postBuilding the WebSocket Event Listener
The WebSocket Event Listener is the heart of our voice AI assistant, handling real-time communication between Twilio’s Conversation Relay and Amazon Bedrock. Let’s explore the key concepts that make this component work.
Understanding the WebSocket Handler
Our WebSocket handler (src/websocket/app.py) processes three types of events:
- Connection events (
$connectand$disconnect): Track when clients connect to or disconnect from the WebSocket API. - Message events (
$default): Process incoming messages from Twilio Conversation Relay, which include:setup: Initializes a new conversation session in DynamoDB.prompt: Contains voice input that needs an AI response.interrupt: Handles user interruptions during AI responses, including what the assistant actually said to the user before being interrupted.
Key Implementation Concepts
In the Lambda function we need to ensure that our voice assistant has everything it needs to provide a proper response, this includes setting the context of the conversation and getting the previous inputs and responses.
We also want to optimize the assistant for real-time response and keep the conversation as natural as possible. This includes streaming responses back to the users as the LLM is generating it and taking advantage of cold starts to initialize static values that can be reused.
1. Optimizing Lambda Cold Starts
We initialize clients outside the handler function to allow further executions of the same runtime to reuse these. This helps in reducing latency.
# Initialize clients outside the handler for Lambda optimization
bedrock_runtime = boto3.client('bedrock-runtime')
dynamodb = boto3.resource('dynamodb')
table = dynamodb.Table(os.environ.get('SESSIONS_TABLE', 'TwilioSessions'))2. Stateful Conversations with DynamoDB
To maintain context across utterances, we store conversation history in DynamoDB:
- Each interaction is identified by the connectionId value. This is used to store and retrieve related events in the db.
- The routeKey identifies the WebSocket event, which allows the assistant to handle events in the conversation. In this example we handle events as follows:
- Log when the user connects and disconnects.
- Initialize the conversation context at setup up.
- Generate responses for voice prompts (user inputs).
- We also get an instance of the API Gateway resource in order to be able to send partial responses from the LLM model back to the user.
# src/websocket/app.py
...
def lambda_handler(event, context):
...
# Extract connection ID and route key
connection_id = event['requestContext']['connectionId']
route_key = event['requestContext']['routeKey']
logger.info(f"Processing {route_key} for connection {connection_id}")
# Get API Gateway management client
domain = event['requestContext']['domainName']
stage = event['requestContext']['stage']
endpoint = f"https://{domain}/{stage}"
client = boto3.client('apigatewaymanagementapi',
endpoint_url=endpoint,
region_name=os.environ.get('AWS_DEFAULT_REGION', 'us-east-1'))
# handle user connecting to the session
if route_key == '$connect':
logger.info(f"Client connected: {connection_id}")
return {'statusCode': 200, 'headers': headers}
# handle user disconnecting from the session
elif route_key == '$disconnect':
logger.info(f"Client disconnected: {connection_id}")
return {'statusCode': 200, 'headers': headers}
# process incoming messages
elif route_key == '$default':
# Process the message from Twilio Conversation Relay
if event.get('body'):
try:
message = json.loads(event.get('body'))
logger.info(f"Message received: {message}")
# handle setup message
if message.get("type") == "setup":
logger.info(f"Setup for call: {connection_id}")
# Initialize session in DynamoDB
save_session(connection_id, [{"role": "system", "content": SYSTEM_PROMPT}])
# handle voice prompts
elif message.get("type") == "prompt":
voice_prompt = message.get("voicePrompt")
logger.info(f"Processing prompt for {connection_id}: {voice_prompt}")
# Get conversation history from DB
conversation = get_session(connection_id)
# Add user message to the conversation
conversation.append({"role": "user", "content": voice_prompt})
# Get AI response with streaming
response = ai_response(conversation, connection_id, client)
# Add assistant response to conversation
conversation.append({"role": "assistant", "content": response})
# Save updated conversation in the DB
save_session(connection_id, conversation)
logger.info(f"Sent streaming response completed")
# Handle interruptions. Nothing to do here for now
elif message.get("type") == "interrupt":
logger.info("Handling interruption.")
# Handle interruption logic here if needed
# handle any other event
else:
logger.warning(f"Unknown message type: {message.get('type')}")
# error handling for events
except Exception as e:
logger.error(f"Error in streaming response process: {str(e)}")
except json.JSONDecodeError:
logger.warning(f"Could not parse body as JSON: {event.get('body')}")
# return HTTP response
return {'statusCode': 200, 'headers': headers}
...3. Streaming Responses for Real-time Voice
The most critical aspect of our implementation is streaming AI responses in real-time. Instead of waiting for the complete response, we:
- Call Amazon Bedrock with
converse_stream()to get a streaming response. - Process each chunk as it arrives.
- Send each text fragment to the client immediately with
last: false.
Send a final message with last: true to signal completion.
# src/websocket/app.py
...
def ai_response(messages, connection_id, client):
...
# call bedrock with converse_stream
response = bedrock_runtime.converse_stream(
modelId=model_id,
messages=formatted_messages,
system=system_message,
inferenceConfig=inference_config
)
# Process each chunk from the stream
full_response = ""
for chunk in response["stream"]:
if "contentBlockDelta" in chunk:
content_text = chunk["contentBlockDelta"]["delta"]["text"]
if content_text:
full_response += content_text
# Send the chunk to the client
client.post_to_connection(
ConnectionId=connection_id,
Data=json.dumps({
"type": "text",
"token": content_text,
"last": False
})
)
# Send final message with last=True
client.post_to_connection(
ConnectionId=connection_id,
Data=json.dumps({
"type": "text",
"token": "", # Empty token for final message
"last": True
})
)
return full_responseThis approach enables Twilio to synthesize speech in real-time as tokens arrive, creating a more natural conversation flow.
4. Adapting the System Prompt for Voice Responses
The system prompt is crucial for voice applications. Note how it’s tailored specifically for voice output:
SYSTEM_PROMPT = "You are a helpful assistant. This conversation is being
translated to voice, so answer carefully. When you respond,
please spell out all numbers, for example twenty not 20.
Do not include emojis in your responses."This helps the AI generate responses that sound natural when converted to speech by Twilio’s text-to-speech engine.
To deploy this function to AWS we create an AWS::Serverless::Function with the proper permissions, and also create an AWS::DynamoDB::Table for storing conversation context. In our case we want to use the newest Amazon Nova Pro model, so we set it using a Parameter.
# template.yaml
...
Parameters:
BedrockModelId:
Type: String
Default: amazon.nova-pro-v1:0
Description: Amazon Bedrock model ID to use
Resources:
# DynamoDB Table for storing conversation sessions
SessionsTable:
Type: AWS::DynamoDB::Table
Properties:
TableName: TwilioSessions
BillingMode: PAY_PER_REQUEST
AttributeDefinitions:
- AttributeName: connection_id
AttributeType: S
KeySchema:
- AttributeName: connection_id
KeyType: HASH
...
WebSocketFunction:
Type: AWS::Serverless::Function
Properties:
FunctionName: twilio-cr-websocket-function
CodeUri: src/websocket/
Handler: app.lambda_handler
Runtime: python3.12
Timeout: 30
MemorySize: 256
Environment:
Variables:
BEDROCK_MODEL_ID: !Ref BedrockModelId
SESSIONS_TABLE: !Ref SessionsTable
Policies:
- AWSLambdaBasicExecutionRole
- DynamoDBCrudPolicy:
TableName: !Ref SessionsTable
- Statement:
- Effect: Allow
Action: execute-api:ManageConnections
Resource: !Sub arn:aws:execute-api:${AWS::Region}:
${AWS::AccountId}:${WebSocketApi}/*
- Effect: Allow
Action:
- bedrock:InvokeModel
- bedrock:InvokeModelWithResponseStream
Resource: '*Setting Up WebSocket Infrastructure for Real-Time Voice AI
Now let’s build the endpoint for the WebSocket connection.
WebSocket API Gateway Resources
The WebSocket infrastructure consists of several interconnected components that work together to enable bidirectional communication:
1. WebSocket API
The WebSocket API is the entry point for all WebSocket connections:
WebSocketApi:
Type: AWS::ApiGatewayV2::Api
Properties:
Name: TwilioWebSocketAPI
ProtocolType: WEBSOCKET
RouteSelectionExpression: $request.body.actionThe RouteSelectionExpression determines how incoming messages are routed. For Twilio Conversation Relay, we use $request.body.action as the default expression, though most messages will be handled by the $default route.
2. Lambda Integration
To process WebSocket messages with Lambda, create an integration:
ConnectRoute:
Type: AWS::ApiGatewayV2::Route
Properties:
ApiId: !Ref WebSocketApi
RouteKey: $connect
AuthorizationType: NONE
Target: !Sub integrations/${WebSocketIntegration}
DisconnectRoute:
Type: AWS::ApiGatewayV2::Route
Properties:
ApiId: !Ref WebSocketApi
RouteKey: $disconnect
AuthorizationType: NONE
Target: !Sub integrations/${WebSocketIntegration}
DefaultRoute:
Type: AWS::ApiGatewayV2::Route
Properties:
ApiId: !Ref WebSocketApi
RouteKey: $default
AuthorizationType: NONE
Target: !Sub integrations/${WebSocketIntegration}These routes handle connection establishment, disconnection, and message processing, respectively.
4. Deployment and Stage
To make your API available, create a deployment and stage:
WebSocketDeployment:
Type: AWS::ApiGatewayV2::Deployment
DependsOn: [ConnectRoute, DisconnectRoute, DefaultRoute]
Properties:
ApiId: !Ref WebSocketApi
WebSocketStage:
Type: AWS::ApiGatewayV2::Stage
Properties:
ApiId: !Ref WebSocketApi
DeploymentId: !Ref WebSocketDeployment
StageName: prod
DefaultRouteSettings:
DataTraceEnabled: true
LoggingLevel: INFOThe DependsOn attribute ensures routes are created before deployment. The stage settings enable logging for easier debugging.
5. Lambda Permission
Grant API Gateway permission to invoke your Lambda function:
WebSocketPermission:
Type: AWS::Lambda::Permission
Properties:
Action: lambda:InvokeFunction
FunctionName: !Ref WebSocketFunction
Principal: apigateway.amazonaws.com
SourceArn: !Sub arn:aws:execute-api:${AWS::Region}:${AWS::AccountId}:${WebSocketApi}/*This permission is essential; without it, API Gateway cannot trigger your Lambda function.
Deploy Your Voice Assistant And Connect It with Twilio
Now it’s only a matter of deploying our assistant to AWS and connecting it with our Twilio number.
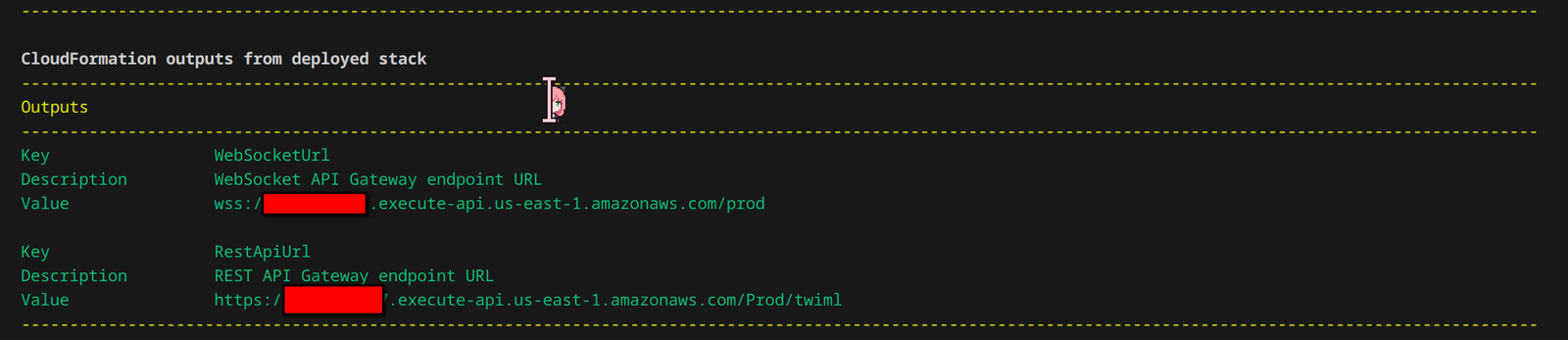
To do so, set up your AWS credentials and run the deploy.sh script. This will internally create all necessary dependencies and use the SAM CLI to build and deploy the required resources in AWS. When it’s done, take note of the URL for REST API Gateway endpoint.
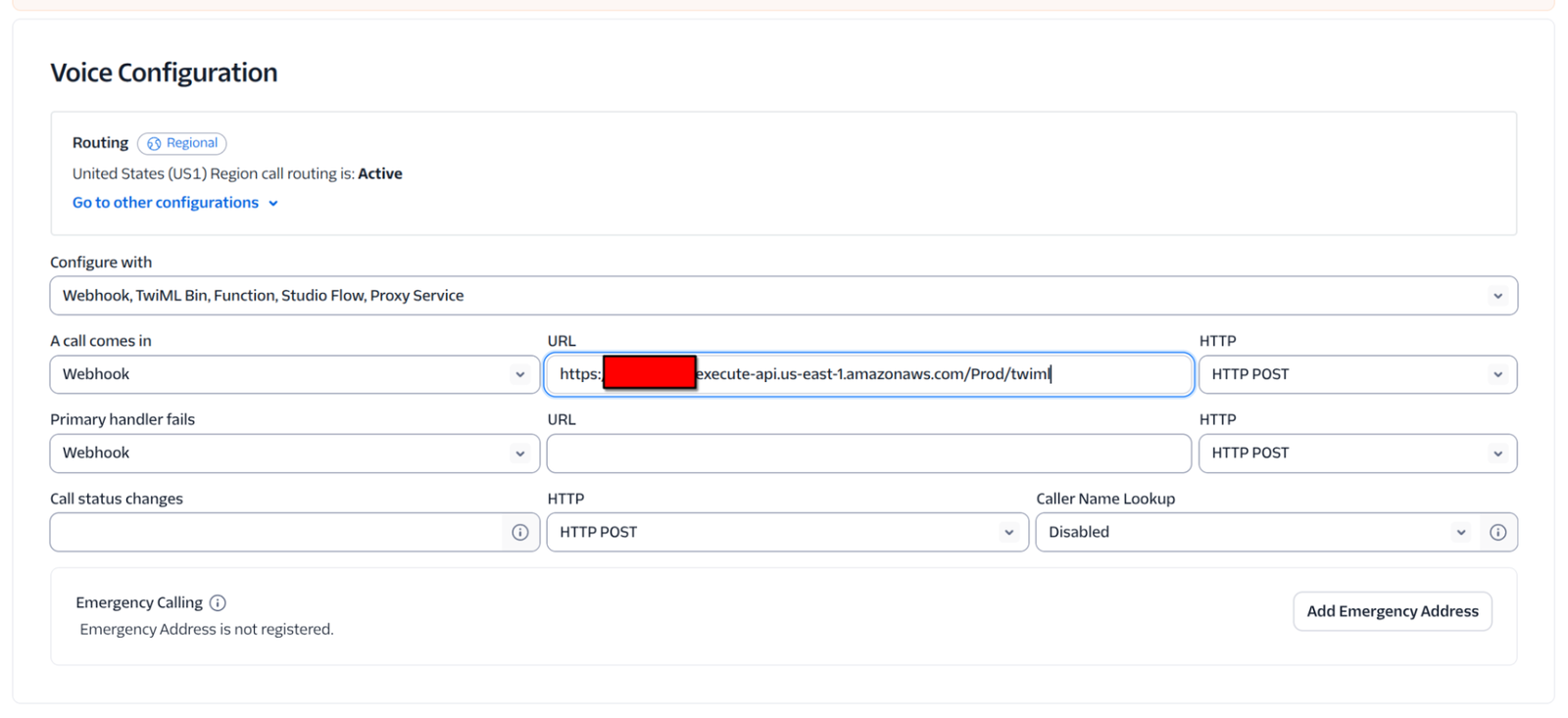
Now go to your Twilio Console and select the phone number where you want your assistant to be available. Under “Voice Configuration”, select “Configure with” as “Webhook, TwiML Bin, Function, Studio Flow, Proxy Service” and set “A call comes in” to the POST endpoint you just created. Click on “Save Configuration”.
Now you can test your voice assistant by calling the phone number.
Operationalizing Telephony-Based Voice AI
In this post, we demonstrated how to implement a real-time, telephony-integrated Voice AI assistant using Twilio ConversationRelay and AWS serverless technologies. By combining Twilio’s programmable voice infrastructure with the scalability of AWS Lambda, API Gateway, and Amazon Bedrock, we created a fully event-driven architecture capable of low-latency audio processing, real-time AI interaction, and dynamic speech synthesis.
This solution pattern enables developers to build maintainable, cost-effective voice experiences that adapt well to production workloads. Through stateless compute and persistent context storage in DynamoDB, the assistant remains conversational, responsive, and interruptible—as expected in any modern voice UI.
The architecture shown here is modular by design—allowing teams to swap models, plug in third-party analytics, or integrate with existing contact center workflows. It serves as a solid foundation for deploying scalable and intelligent voice-powered applications across real-world telephony environments.
Whether you’re building a proof of concept or preparing for production, implementing real-time Voice AI for telephony requires careful attention to latency, scalability, and integration workflows. If you’re exploring how to adapt this architecture to your environment or want guidance on optimizing and extending it, our team at WebRTC.ventures has deep experience designing and deploying custom conversational solutions. We’re happy to collaborate on your project and help bring real-time, voice-first applications to life. Contact us today to discuss your project and unlock the full potential of your voice AI initiatives!
Further Reading:
- Twilio’s ConversationRelay GA Release Brings Voice AI to the Enterprise Mainstream
- WebRTC SIP Integration: Advanced Techniques for Real-Time Web and Telephony Communication
- A Serverless Approach to Post-Call Analysis Using AWS Lambda, Amazon Transcribe, and Amazon Bedrock
- Building a Smart IVR Agent System with LiveKit Voice AI: Say Goodbye to “Press 1 for Sales”
- How to Build a Custom Integration to External Telephony for your CPaaS-based WebRTC App










