
AI and LLMs are everywhere these days. In contact center applications, they are the key to implementing next generation post-call analysis, making manual work by supervisors and third party surveys a thing of the past. AI-based post-call analysis provides an automated approach to capture recordings of customer service or sales calls, transcribe them, and then leverage an LLM to analyze the activities to evaluate agent effectiveness, identify areas for improvement, and gain a range of other targeted insights valuable to a specific company or process.
However, setting up AI-based post-call analysis is not exactly a walk in the park. There are many intricacies in the contact center’s underlying infrastructure and application requirements that often make it too expensive or simply not viable for the company. A serverless approach to post-call analysis is therefore a great option.
Surprisingly, “serverless” does not mean there are no servers involved, rather it means that the servers are managed in the cloud by a third party service like AWS Lambda. AWS Lambda runs your code in response to events and automatically manages the compute resources. It is not only cost-effective, but also simplifies the management of the pipeline.
In this post, we will delve into the details of how to implement a serverless approach to AI-powered post-call analysis using AWS Lambda as the serverless solution, Amazon Bedrock to integrate and deploy the generative AI capabilities, and Amazon Transcribe as the machine learning service to automatically convert speech to text and extract insights.
But first, let’s run through the process of selecting an AI model that is right for your project.
AI Model Selection
When selecting an AI model, the first thing you need to consider is whether it supports the features you need. For post-call analysis, you are interested in two things:
- Transcribing conversations
- Processing the resulting transcript through an LLM in order to generate insights
Next, you need to check how your application will talk to the models. Some vendors, such as Symbl.ai and OpenAI, offer their models through their own APIs that you can connect to without any additional effort. Others require you to download the model and host it on your own.
This is where things can get complicated. Provisioning and maintaining an AI model easily becomes a project on its own that without the proper expertise can lead the whole effort to failure. You can take advantage of powerful cloud services such as Amazon EC2 to spin up servers and then add tools like Ansible, Terraform or Packer to automate such a process. However, you would also need to set up a mechanism that allows you to keep these servers available and up-to-date. Not to mention the domain-specific set of skills for optimizing the models to the task your application is performing.
On top of that, you need to pay for these resources. Unless you do a great job at capacity planning – another thing that easily becomes a project on its own – you’ll end up with unused resources that eat up your budget.
Interacting with your AI Model
The next step is to make your application interact with the model. This includes extracting and preparing the data, and then sending it using whichever method is supported by the model. This adds an extra load to the application, which now has to process additional data and deal with another set of services, potentially impacting its performance.
The above is true whether you use a model provided by a vendor or you’re hosting it on your own.
No Servers, No Cry!
Using AI models from a vendor like Symbl.ai or OpenAI is not always possible, and without the proper expertise and resources, implementing an infrastructure like mentioned above might be a cumbersome task. And let’s not forget that there is an actual application you need to build!
This is where a serverless approach fits. As we said earlier, this doesn’t mean a server isn’t involved. It is just managed by someone else. And the best part? You only pay for what you use. This allows you to get the features you need without worrying about the underlying infrastructure that makes these work. You can focus on building your application!
AWS offers a set of fully managed services that checks all our boxes with regard to implementing post-call analysis in a cost-effective manner, without the infrastructure overhead. Let’s dive in!
WebRTC.ventures is a proud member of the global community of developers who have attained an approval badge as an official AWS Partner. We’ve met a vigorous set of criteria, including knowledge, experience, and customer success requirements.
Amazon Transcribe: Real-time ML-powered conversation insights
Amazon Transcribe is a generative AI-powered API for generating highly accurate call transcripts and extracting conversation insights. It supports transcribing over 100 languages both in batch and in real-time. It even works with those low-fidelity phone audio inputs that are common in many contact centers!
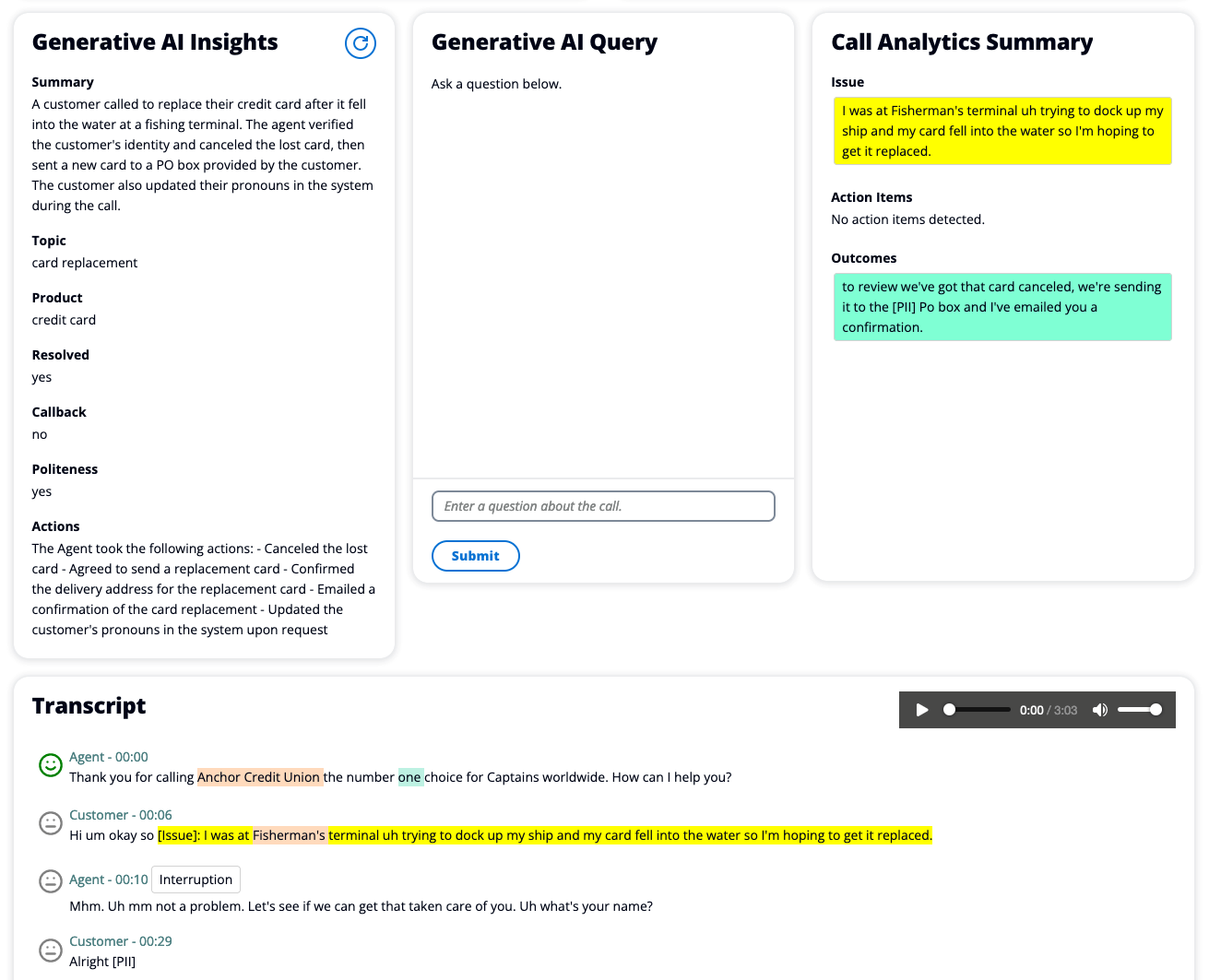
Integration of Amazon Transcribe can be performed through their REST API endpoints or their Software Development Kits (SDKs) available for multiple languages: including NodeJS, Python and Ruby. Then it’s only a matter of creating transcription jobs that will take your call recordings and transcript them.
Amazon Bedrock: Build and scale generative AI applications with foundation models
Amazon Bedrock is a managed service that lets you access multiple Foundational Models (FM), such as Meta’s Llama 2, Anthropic Claude (Claude 3 coming soon!) and Amazon Titan, in an easy and straightforward fashion. It provides a nice interface to experiment with and customize different models, without worrying about nor paying for the underlying infrastructure that supports these, other than for what you really use.
It also provides customization options for fine-tuning your models to adapt them to your needs and specific use case, at the same time that gives you full control over the data you fed into them. Meaning that you can add specific business rules into your post-call analysis without worrying about these being disclosed or used by a third party.
AWS Lambda: Run code without thinking about servers
AWS Lambda allows you to run your code on demand. In our use case, it acts as the glue between AI capabilities and your application. You can pair it up with other services such as Amazon S3 to build powerful automated pipelines that are triggered when you upload an audio recording without any intervention.
This frees up your application from having to deal with processing the data, and focus on what it needs to do, while you leverage the robust and scalable cloud infrastructure provided by AWS to do the rest.
Adding AI-Based capabilities without the infrastructure overhead
By combining the three tools, you can easily set up a powerful pipeline to perform post-call analysis for your contact center application. All without having to provision, maintain and pay for a single server, and instead leveraging a robust and scalable infrastructure.
Stay tuned for a future post where we take a technical approach to guide you through the steps to build such a pipeline.
If you’re interested in adding post-call analysis or any kind of other AI-based capabilities to your real-time communication application, our team at WebRTC.ventures has the expertise you need. Contact us today. Let’s make it live!
Related posts:









