
In my last post, Building an AI Travel Agent with Symbl.ai’s Nebula LLM and Amazon Connect, I spoke about how the integration of Generative AI tools are transforming the landscape of call centers, virtual meetings, and many other businesses. I guided you through building an AI Travel Agent leveraging Symbl.ai and AWS that can proactively make personalized recommendations based on a caller’s spoken input and even go as far as to detail flight and accommodation options. All without the need for a human agent.
Now, let’s flip the scenario slightly and turn our AI into a co-pilot, providing Agent Assist to a human agent rather than acting on its own. With instant, AI-enhanced suggestions from the LLM, agents have quick and easy access to a vast amount of up-to-date information to identify, propose, and book our customer the trip of a lifetime (or just to visit me in Punjab!) Symbl’s conversational AI tools can step in after the call with everything from summaries and action items to quality scores.
All of this takes place within Amazon Connect, the AWS cloud-based contact center. A significant advantage of Amazon Connect is its ability to seamlessly integrate with other AWS services and third-party applications, such as we are doing today with Symbl.ai’s Nebula LLM and Streaming API. Please refer back to my previous post to learn more about the powerful features and benefits of these three main players in this project.
I hope these posts are a portal to understanding how these powerful tools can be harnessed to redefine the standards of customer interaction, agent assistance, and post-call analysis. We’re not just talking about incremental changes; we’re delving into a paradigm shift that empowers agents with unparalleled insights and efficiency in the travel industry, and many others.
Technologies Used:
- Symbl.ai
- Symbl.ai Nebula LLM
- Amazon Connect
- amazon-connect-stream library
- connect-rtc.js library
- Next.js
- Tailwind CSS
- Ant Design
Prerequisites
You will need access to the following;
- A pair of appId and secret for Symbl.ai, which you can get from the platform’s main page. We use these to retrieve a temporary access token.
- An API Key for Nebula LLM, which you get by joining the beta wait list.
- A pair of Access and Secret keys for the AWS account where Amazon Connect is configured.
Symbl.ai and Nebula Integration Architecture
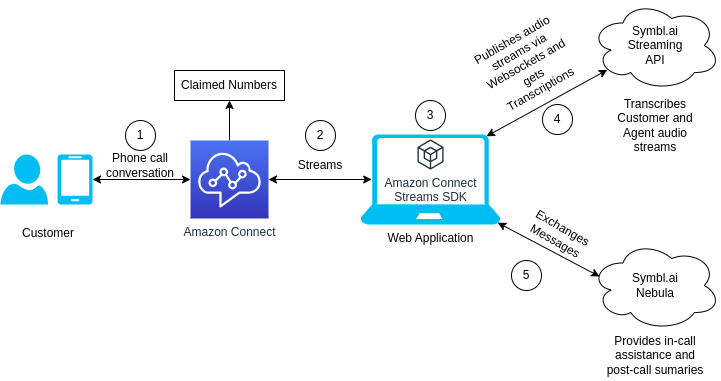
The architecture looks like this:
- The customer calls to one of Amazon Connect claimed numbers. This is where the conversation happens from the point of view of the client.
- Amazon Connect streams the audio stream to a web application. This is where the conversation happens from the point of view of the agent.
- The web application runs the Amazon Connect Streams SDK in order to have the Contact Center Panel bundled in the web page.
- The application publishes the audio streams to Symbl.ai Streaming API via a web socket connection. The API then transcribes both customer and agent streams and sends these back to the application through the same channel.
- Once the transcriptions are available in the application, these are sent as messages to Symbl.ai Nebula LLM in order to get in-call assistance and post-call summaries back to it.
These steps are depicted in the diagram below:
Connecting to Symbl.ai Streaming API
The first step is to set up Amazon Connect’ SDK, amazon-connect-streams, along with the connect-rtc-js library. This was already covered in a previous post, building an AI Travel Agent using Symbl.ai’s Nebula LLM and Amazon Connect . The rest of this post assumes that you have access to both customer and agent audio streams from the web application.
Afterwards, start by generating a unique identifier as follows:
connectionId = crypto.randomUUID();We use this generated connectionId for connecting to Symbl.ai Streaming API in order to get customer and agent transcriptions for a given session. The process goes like this:
- We create a WebSocket connection by passing in the symblToken mentioned in prerequisites, and the connectionId we just generated.
- We then bind the various events to the connection namely:
- onmessage: called anytime we receive a message from the socket server,
- onerror: called anytime we receive an error to the from the socket server,
- onclose: called anytime the opened socket connection closes,
- onopen: called anytime the websocket connection is established.
With this in place, we call the function 2 times, one for each user, passing the same connectionId so they join to the same connection.
// A function for creating a WebSocket connection.
// It receives the connectionId and the type of user (agent or customer)
const createWsConnection = useCallback(
({
connectionId,
userType,
}: {
userType: UserType;
connectionId: string;
}) => {
// points to Symbl.ai Streaming API endpoint
const socket = new WebSocket(
"wss://api.symbl.ai/v1/streaming/" +
`${connectionId}?access_token=${symblToken}`
);
// binding the listeners
socket.onmessage = (e) => handleMessage(userType, e);
socket.onerror = (e) => handleError(userType, e);
socket.onclose = (e) => handleClose(userType, e);
socket.onopen = () => {
onSocketOpen(socket, userType);
};
return socket;
},
[handleClose, handleError, handleMessage, onSocketOpen, symblToken]
);
Setting up In-Call Assistance for Agents
- We start by checking the type of message, which could be any of the ones defined in the Streaming API reference page.
- Then we check if a transcription is available.
- When our dormancy detection algorithm detects a stop in speech, and if the conditions are fulfilled, we call the sendToNebula() function.
Now let’s see how to assist the agent during calls in real-time. We do this in the handleMessage that we binded to the onMessage event listener as follows:
// we call this function when a message is received
const handleMessage = useCallback(
(userType: UserType, e: any) => {
if (userType === "agent") return;
const data = JSON.parse(e.data);
// check if a transcription is available
if (
data.type === "message" &&
data.message.hasOwnProperty("punctuated")
) {
// get the transcription
const text = data.message.punctuated.transcript;
// detect a stop and speech and validate if the conditions are fulfilled
if (setUserRealtimeTranscript) {
setLocalTranscription(text);
setUserRealtimeTranscript(text);
localMessageRef.current = text;
if (timerId?.current) {
clearTimeout(timerId.current);
timerId.current = setTimeout(() => {
sendToNebula();
}, USER_SPEECH_INACTIVITY_INTERVAL);
} else {
timerId.current = setTimeout(() => {
sendToNebula();
}, USER_SPEECH_INACTIVITY_INTERVAL);
}
}
}
},
[sendToNebula, setUserRealtimeTranscript]
);
The sendToNebula function concatenates all the messages of the user into an array of messages called messagesFromSymbl. We then send that single array to Nebula using the callNebulaStreaming function which we will describe later.
const messagesFromSymbl = [...messages, localMessageRef.current]
.join("\n");
const response = await callNebulaStreaming(messagesFromSymbl);
if (!response) return;
await processResponseFromNebula({
response,
});Now let’s take a look at the callNebulaStreaming function:
- First, we check if a Nebula request has already been fired, if so, we terminate the previous request and continue with a new one. To do so, we create a new abortController object, which is the one that handles termination of a request in case it already exists when called multiple times.
- Next, we make a request to the Nebula Streaming API server passing in the list of messages, in our case nebulaMessagesRef.current, and the system_prompt, which is used by the Nebula LLM to decide on the question to answer to. Afterwards we return the response.
const callNebulaStreaming = useCallback(
async (messageToSend: string) => {
// check if a request already exists
if (abortControllerRef.current) {
abortControllerRef.current.abort();
}
// create a new AbortController in case we might want to
// cancel this new request
abortControllerRef.current = new AbortController();
nebulaMessagesRef.current = [
...nebulaMessagesRef.current,
{
role: "human",
text: messageToSend,
},
];
// making a request to the Nebula Streaming API
const response = await fetch(NEBULA_STREAMING_URL_SSE, {
method: "POST",
headers: {
"Content-Type": "application/json",
ApiKey: nebulaApiKey ?? "",
},
body: JSON.stringify({
// the list of messages
messages: nebulaMessagesRef.current,
// the system prompt
system_prompt:
"Assume that you are a travel agency sales agent. " +
"Also assume you know everything about traveling, " +
"vacation, etc. Respond politely to the customer " +
"based on the messages provided. The text generated " +
"shouldn't be more than 4 lines.",
}),
});
return response;
},
[nebulaApiKey, nebulaMessagesRef]
);You can find more info about Nebula API in the Nebula Chat reference page.
Getting Post-Call Summaries
When the call ends we call nebula to provide us with the summary of the conversion. The flow is the same as the callNebulaStream() function but now with a single message and a different system_prompt for gathering summaries:
const callNebulaForSummary = useCallback(
async (messageToSend: string) => {
if (abortControllerRef.current) {
abortControllerRef.current.abort();
}
abortControllerRef.current = new AbortController();
nebulaMessagesRef.current = [
{
role: "human",
text: messageToSend,
},
];
const response = await fetch(NEBULA_STREAMING_URL_SSE, {
method: "POST",
headers: {
"Content-Type": "application/json",
ApiKey: nebulaApiKey ?? "",
},
body: JSON.stringify({
messages: nebulaMessagesRef.current,
system_prompt:
"Provided a conversation between a customer a sales " +
"agent. Generate a comprehensive summary of the " +
"conversation. The summary should be no more than " +
"100 words",
}),
});
return response;
},
[nebulaApiKey, nebulaMessagesRef]
);
Time for a Demo for AI Agent Assist in Action!
Ready to build your AI Agent Assist?
You’ve seen how these powerful Generative AI tools can be harnessed to redefine the standards of customer interaction, agent assistance, and post-call analysis. If you’re ready to empower your agents with unparalleled insights and efficiency, contact the integration experts at WebRTC.ventures today!









