
For developers building real-time voice applications like our team does at WebRTC.ventures, 2024 has been an exciting year. OpenAI’s Realtime Audio API and open-source alternatives offer new and distinct approaches to integrating live voice capabilities. As WebRTC and real-time AI converge, the right choice depends on your application’s needs for latency, scalability, and control.
In this post, we’ll compare OpenAI’s multimodal API with open-source solutions, examining their architectures, integration complexity, customization options, and latency performance to help you make an informed choice for voice-enabled WebRTC applications.
For a deeper dive into OpenAI’s Real-Time API, check out a recent post by our WebRTC Developer Advocate, Hector Zelaya: OpenAI’s Realtime API: AI Goes Multimodal.
Recent History and Traditional Conversational AI Architecture
As real-time audio processing gained traction in recent years, OpenAI and other cloud providers developed modular services to handle various aspects of audio interactions. The traditional AI audio solution follows a sequential pipeline:
- Voice input is captured
- Speech-to-Text (STT/ASR) converts audio to text
- Large Language Models (LLMs) process the text for comprehension
- Text-to-Speech (TTS) converts responses back to audio
This modular approach supports various applications, including:
- Compliance alerts
- Keyword detection
- Real-time suggestions during calls or meetings
The architecture looks like this:

While this pipeline is functional and widely used in production, its segmented, multi-step approach can introduce latency that impacts performance in conversational AI applications.
Streamlined OpenAI Real-Time Architecture Using LMM
By utilizing a multimodal large language model (LMM), we can process speech in a unified way, eliminating the traditional pipeline of separate speech-to-text and text-to-speech conversions.
This direct approach enables the model to “hear” and understand voice input, including subtle emotional nuances that often get lost in traditional conversion methods. The architecture is enhanced with server-side Voice Activity Detection (VAD) to precisely identify speech endpoints and pauses, creating a more natural interaction flow.
The architecture looks like this:

Still, a give and take
Multimodal models can be more resource-intensive due to audio processing and, as of today, are not as accurate.
Additionally, audio needs to be sent via WebSockets and in one of the following formats:
- Raw 16 bit PCM audio at 24kHz, 1 channel, little-endian
- G.711 at 8kHz (both u-law and a-law)
These uncompressed audio formats may lead to higher latency and increased bandwidth consumption, which aren’t optimal for real-time communication. For example, latency in this test increased almost 50% in a 15% packet loss network when using WebSockets.
While I won’t go into deep technical comparisons here, it’s interesting to see how OpenAI’s Real-Time API and open-source alternatives are innovating in this area. Each of these solutions offers unique approaches, especially when integrated with WebRTC or CPaaS platforms, creating new possibilities for voice-driven applications in real-time communications.
Open-Source Alternatives to OpenAI’s Real-Time Audio API
Let’s take a look at some open source alternatives.
LiveKit Agents
LiveKit stands out as a modern Go framework for real-time communication, focusing on audio and video processing. It’s engineered for scalability and can be tailored to various applications, offering APIs that allow for the development of custom communication agents.
You can test their demo here: LiveKit Agents Playground: KITT
The flow is expected to look as follows:
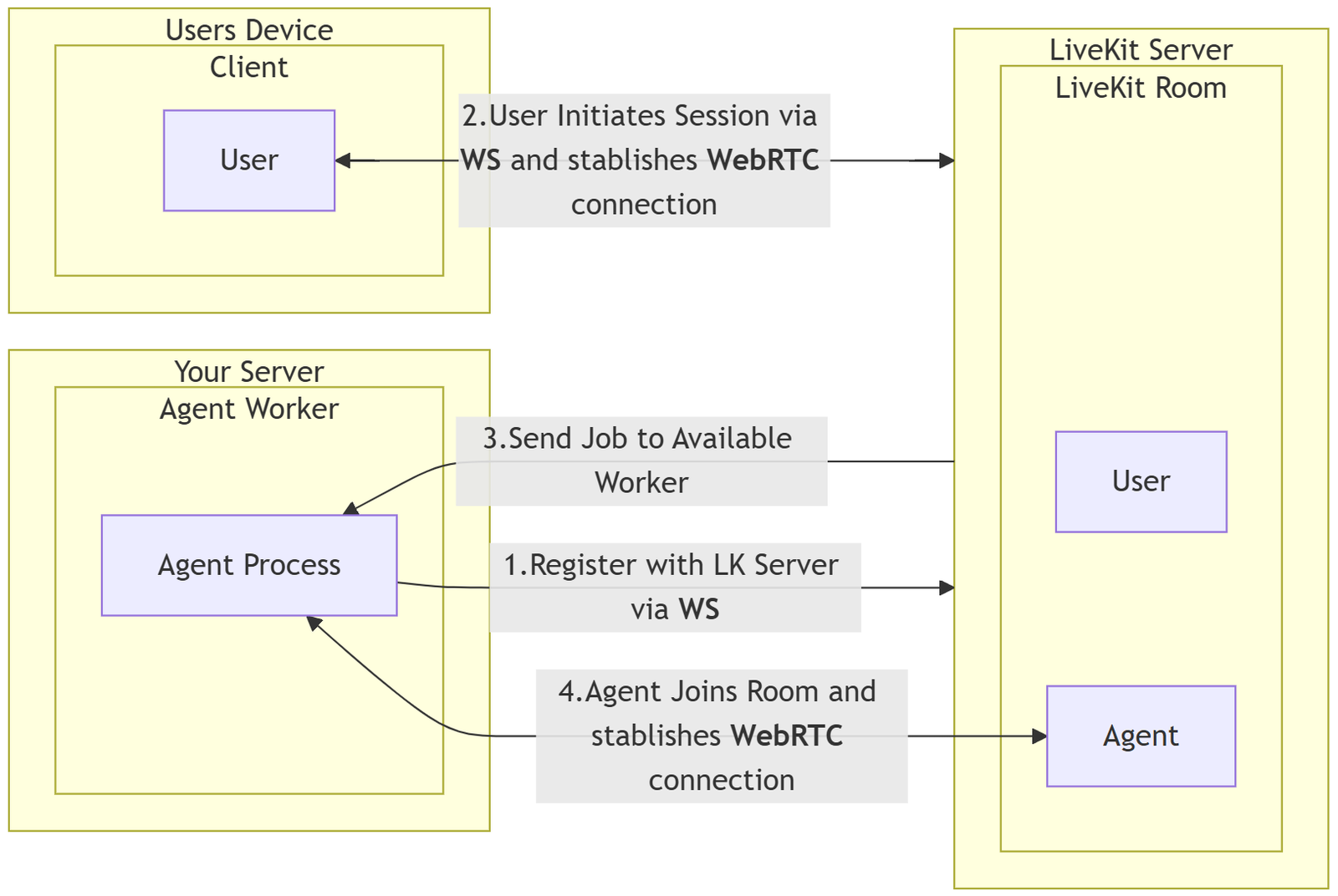
The integration with WebRTC means low-latency interactions, and the option for self-hosting provides developers with control over their infrastructure. After these steps, audio will start being processed by the Agent Process as follows:
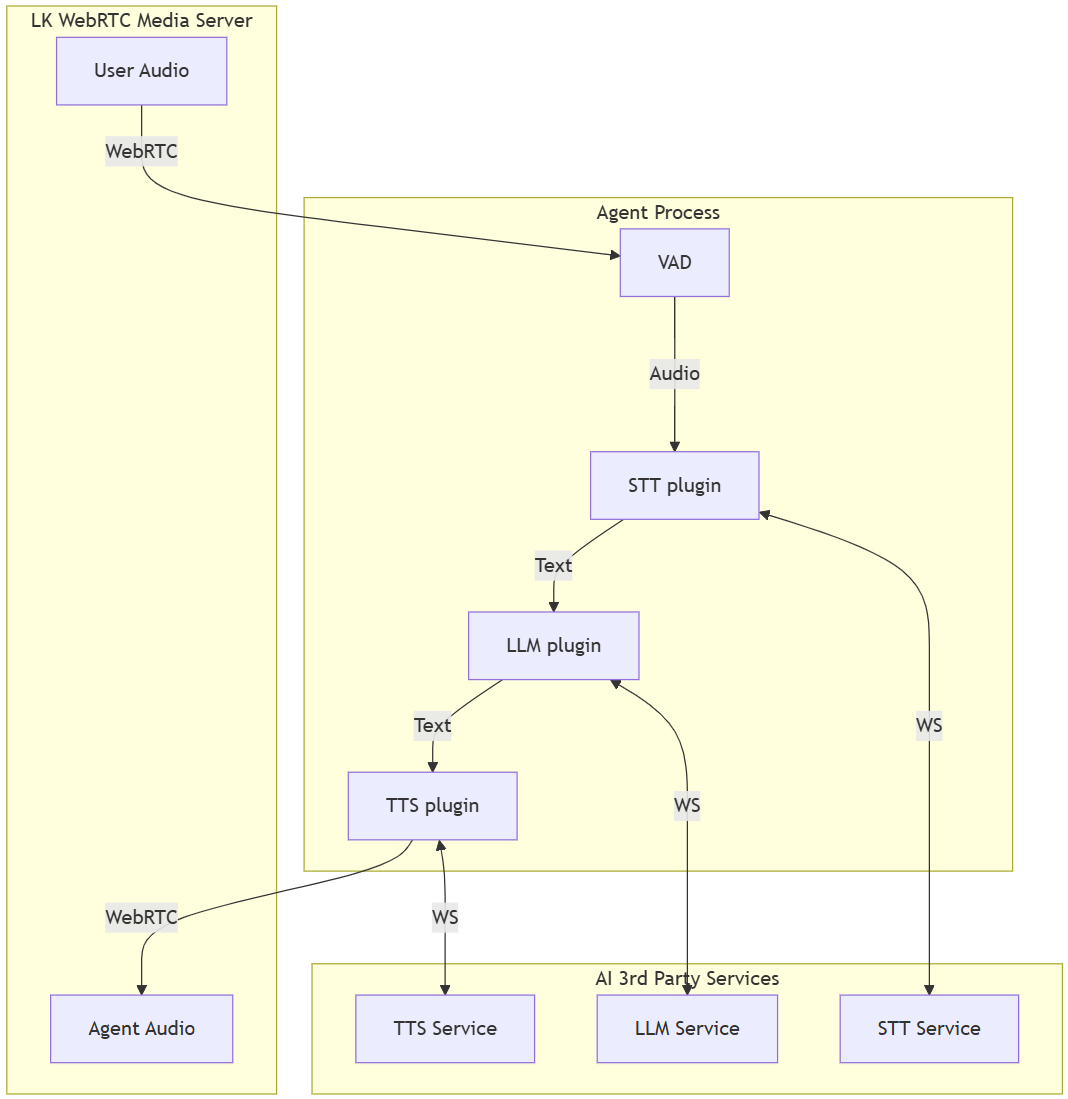
Following this diagram, we can identify the main high level elements of the pipeline:
- The VAD (Voice Activity Detection) initiates Audio to STT Plugin (Speech-to-Text).
- STT Plugin converts speech to Text for the LLM Plugin (Language Model).
- The LLM Plugin processes and routes Text to TTS Plugin (Text-to-Speech), which produces Agent Audio.
- The WebSocket (WS) integration via WS to the third-party TTS Service and forwarding of the audio via WebRTC.
LiveKit recently began offering an integration with the OpenAI Real Time API to facilitate this more direct multimodal approach: LiveKit Docs.
PipeCat
PipeCat is designed for building real-time voice (and multimodal) conversational agents. Similar to the previous implementation, this Python framework pipelines enable developers to create custom audio pipelines tailored to specific use cases like meeting assistants, customer support bots or social companions.
PipeCat uses aiortc for WebRTC and integrates with Daily for real-time video and audio. It also supports WebSockets, LiveKit, and local sockets as transport mechanisms. With built-in support for many leading transcription, LLM, and voice AI services, including the latest OpenAI Realtime API, PipeCat is designed to scale seamlessly across diverse AI and communication platforms.
A high level diagram of an AI agent pipeline built with PipeCat could look like this:
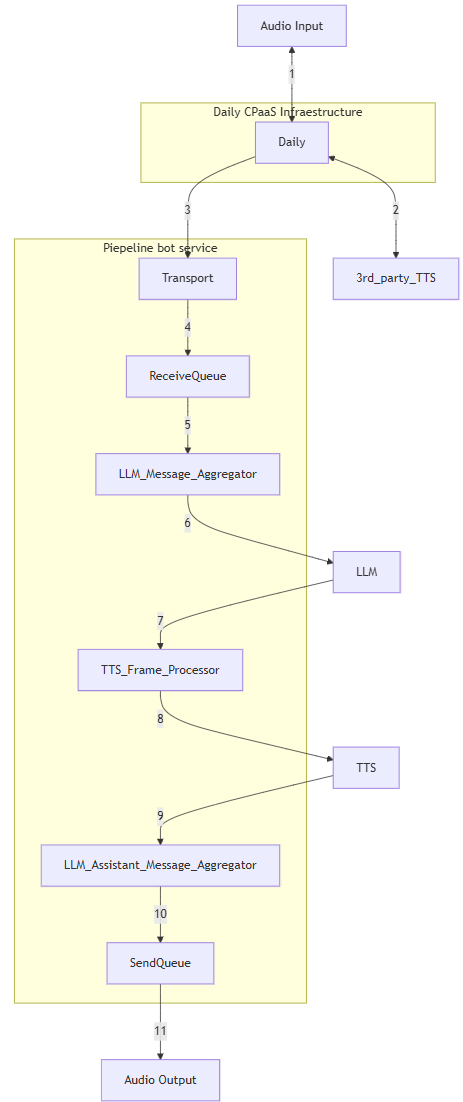
However, if you’re looking for a fully open-source WebRTC solution, you would need to deploy your own open source media server and deliver media using the available PipeCat transports or by developing a custom transport. More information about the specific components can be found at pipecat/docs/architecture.md at main · pipecat-ai/pipecat.
Ultravox
Unlike the previous solutions focused on integrating third-party services, Ultravox is an open-source Speech Language Model (SLM) capable of real-time voice inference, similar to the new OpenAI Real-Time API. Ultravox emphasizes on the model architecture itself rather than the capture or delivery of audio data, making it adaptable to platforms like LiveKit or Daily.
For those wanting a managed audio setup, Ultravox also offers a non-open-source API and SDKs, which handle real-time media connections and delivery.
Built on Meta’s Llama 3, Ultravox can be fine-tuned for specific use cases, languages, or even swapped out with other LLMs for custom implementations. Currently, the open-source version doesn’t generate audio directly, so any text output still requires a text-to-speech (TTS) service for voice responses.
Here is the Ultravox SLM open source version architecture:
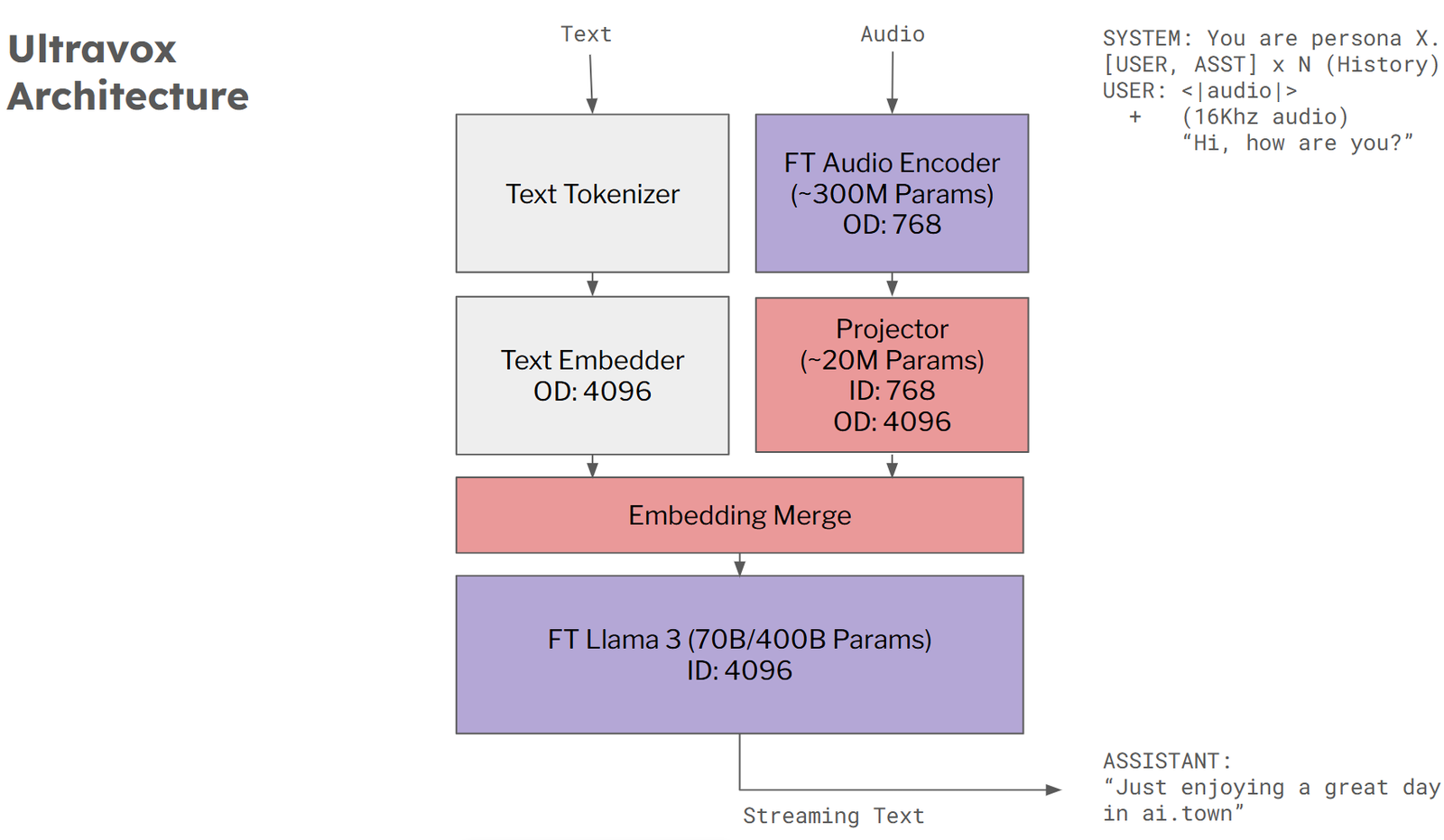
Their repository can be found here: fixie-ai/ultravox: A fast multimodal LLM for real-time voice. And you can test their demo here: Ultravox Demo.
Additional Options in the CPaaS Space
Generative AI capabilities are also expanding in CPaaS platforms like Agora, SignalWire, Twilio, and Vonage. These providers are incorporating real-time voice and text services that complement WebRTC applications, catering to developers interested in a managed service with built-in AI capabilities.
Specialized platforms like AssemblyAI and Symbl.ai also offer high-quality STT, TTS, and text analysis services tailored for specific industries. We will talk about some of them in future blog posts!
If you’re looking to build AI-driven real-time applications, WebRTC.ventures is here to help you harness the power of WebRTC and AI for superior communication experiences. Gain a competitive edge for businesses large and small. Request a Free AI evaluation today!










