
One of the biggest challenges in building real-time AI voice agents is the delay between when a user finishes speaking and when the system responds, known as latency. Even small delays in a Voice AI application can disrupt the natural flow of conversation and harm your user experience.
To consistently achieve the kind of sub-second responsiveness necessary for human-like conversational flow without sacrificing answer quality, the webrtc-agent-livekit project takes a holistic approach. It combines the real-time capabilities of the WebRTC-based LiveKit Agent framework, low latency transcription models, and a parallel execution strategy: a fast-response Small Language Model (SLM) to deliver a quick initial reply, and a more advanced Large Language Model (LLM) to generate a detailed follow-up.
This blog post explores the implementation of a parallel LLM architecture using the LiveKit WebRTC framework. We’ll walk through:
- How the system works using LiveKit Agents and low-latency transcription tools
- The logic behind parallel model execution
- Implementation details including asynchronous Python code
- Configuration tips for optimizing your SLM
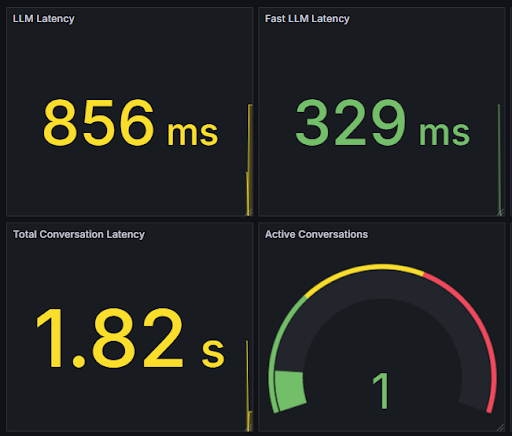
Observability insights using Grafana will be the subject of a follow-up post.
Why Latency Matters for Voice Agents
Delays between a user’s question and an AI agent’s response can break conversational flow, make an interaction feel unnatural, and cause users to disengage. A recent study by the International Journal of Human-Computer Interaction, The Influence of Response Time and Feedback Type on the User Experience of Voice Interaction among Older Adults, revealed that delays over 2 seconds noticeably reduce trust and usability.
This means that for truly conversational experiences, voice agents should respond in under one second. This level of responsiveness helps keep interactions fluid and human-like.
But hitting that target isn’t easy with so many factors introducing latency.
The Architecture Behind SLM + LLM Execution
This implementation is built on the LiveKit Agents framework which provides a powerful foundation for building real-time Voice AI agents. LiveKit handles the WebRTC communication, allowing the AI avatar to participate in audio conversations with low latency and high reliability. In this architecture, the LiveKit media server is running locally.
The LiveKit Agents framework includes:
- Audio streaming and processing capabilities
- Speech-to-text (STT) integration with various providers
- LLM integrations with open source or proprietary alternatives like Ollama or OpenAI
- Text-to-speech (TTS) capabilities for voice output
- Voice activity detection (VAD) and a small turn detection model for determining when users finish speaking
- Session management for handling conversations
The core of our implementation is in the agent-worker directory, specifically in the fast-preresponse.py and fast-preresponse-ollama.py files. These files are two examples that contain the logic for our parallel LLM approach, acting as a bridge between the user’s audio input and the language models.
The agent-worker processes incoming audio, detects when the user has finished speaking (using a new turn detection model: LiveKit turn detector plugin | LiveKit Docs), transcribes the speech (using a 3rd party platform, Deepgram), generates responses using the language models (using OpenAI), and converts those responses back to speech (also using OpenAI). This entire pipeline is optimized for minimal latency at each step.
Keep in mind that using the turn detection model adds an additional latency of approximately 100-200ms.
Parallel Model Execution
The strategy here is the parallel execution of two language models:
- Small Language Model (SLM): A lightweight, fast model that can generate initial responses quickly
- Large Language Model (LLM): A more powerful model that generates higher-quality, more comprehensive responses
Instead of waiting for the larger model to complete its response, we immediately begin generating a response with the smaller model. This allows us to start speaking much sooner, reducing the perceived latency for the user.
Streaming Response Generation
Both the small and large language models use a streaming architecture, where tokens are generated and processed incrementally rather than waiting for the complete response. This further reduces latency by allowing the system to begin speaking as soon as the first few tokens are available.
The code snippet below from the implementation shows how the streaming is handled:
#Let LLM reply to be aware of this "silence filler"
#response
fast_llm_fut = asyncio.Future[str]()
async def _fast_llm_reply() -> AsyncIterable[str]:
filler_response: str = ""
async for chunk in self._fast_llm.chat(
chat_ctx=fast_llm_ctx
).to_str_iterable():
filler_response += chunk
yield chunk
fast_llm_fut.set_result(filler_response)
# We don't need to add this quick filler in the
# context
self.session.say(
_fast_llm_reply(),
add_to_chat_ctx=False
)
filler_response = await fast_llm_fut
logger.info(
f"Fast response: {filler_response}"
)
turn_ctx.add_message(
role="assistant",
content=filler_response,
interrupted=False
)This asynchronous approach allows the SLM to generate quick responses immediately passing them to the TTS system while also collecting the complete response through the standard LLM function.
Configuring the SLM for Quick Responses
The SLM is configured to provide quick, concise responses. Since its primary purpose is to reduce initial response latency, we optimize for speed rather than comprehensive answers.
Key configuration aspects:
- A smaller context window to reduce processing time (we even truncate user input)
- A lower temperature for more deterministic responses
- Potentially, a specialized prompt that encourages brief initial responses
Managing the Parallel Execution of Models
The parallel execution is managed through Python’s asynchronous programming features. The implementation uses asyncio Asynchronous I/O to run both models concurrently without blocking the main thread.
The process works as follows:
- When the user finishes speaking, both models are initiated simultaneously
- As soon as the SLM begins generating tokens, they are sent to the TTS system
- The user hears the SLM’s response while the LLM continues generating its more comprehensive answer. But the SLM response is not added to the chat context (
add_to_chat_ctx=False) - The final LLM response is added to the conversation context for continuity
A Practical Example of a Basic Agentic System
This architecture goes beyond just reducing latency. It’s a practical example of a basic agentic system. By combining fast transcription, the LiveKit Agent framework, and parallel language models, it enables voice agents to respond quickly while still producing high-quality answers.
Key takeaways:
- Fast response time is critical for natural conversations. Sub-second replies help maintain flow and make the agent feel more human.
- Parallel execution of SLM and LLM allows the system to deliver an immediate short reply, then follow up with a more thoughtful, accurate one.
- Agent-like behavior emerges from how the system listens, responds, and updates the conversation context asynchronously. It reacts in real time, without blocking or waiting on long computations. Allowing for fully customizable and complex flows.
- There’s room for optimization: current architecture relies on multiple third-party APIs, some of which (like OpenAI TTS) introduce cloud latency. Co-locating services or running them on edge infrastructure could cut that down significantly.
As language models continue to improve, this architecture offers a strong foundation for building more advanced, real-time voice agents that are both responsive and intelligent—moving us closer to voice interfaces that feel less like tools and more like collaborators.
Demo time!
Toward More Responsive, Real-Time Voice Agents
Reducing latency in AI-powered voice agents isn’t just a technical optimization. It is essential to creating natural, human-like interactions. By combining fast transcription, WebRTC streaming via LiveKit, and parallel execution of Small and Large Language Models, you can significantly improve responsiveness without sacrificing the quality of your AI’s replies.
This architecture not only solves a key UX challenge but also lays the groundwork for more advanced, agentic behavior in real-time applications. With tools like asynchronous streaming, real-time audio pipelines, and intelligent turn detection, we’re moving closer to voice interfaces that feel truly collaborative.
If you’re building a Voice AI solution and want to explore how technologies like LiveKit and WebRTC can help you deliver faster, smarter experiences—our expert team at WebRTC.ventures can help. We’re specialists in real-time communications and agent architectures, and we’re proud to be a trusted LiveKit development partner.
Contact us at WebRTC.ventures to bring your real-time voice agent to life!
Further Reading:
- The Latency Puzzle: Cracking the Code for Real-Time Applications
- When Humans and AI Share the Interface: A Case Study in Multimodal, Adaptive UX
- Optimizing Prompts for Real-Time Voice AI
- AI Voice Agents That Collaborate and Contribute











