
Systematically transcribing, summarizing, and analyzing contact center calls reveals critical data. This information can be used to improve efficiency, enhance the customer journey, uncover business trends, ensure compliance, and much more. With AI and ML, there’s no reason for contact centers to operate ‘in the dark.’
To address this need, we’ve combined three powerful AWS services and built a data-driven dashboard that can be tailored to deliver actionable insights specific to your industry and operations. This solution drives greater efficiency and unlocks your contact center’s full potential.
- Amazon Transcribe converts audio files into text for analysis.
- Amazon Comprehend then extracts key phrases, insights, and sentiment.
- Finally, Amazon Bedrock summarizes calls and performs compliance checks based on your provided regulations.
In this tutorial, we’ll guide you through building an AWS-powered transcription analysis platform that delivers customizable insights into customer interactions within contact centers. We’ll also create a corresponding dashboard using Next.js and TypeScript, a modern web stack that enables a responsive and efficient interface for visualizing the data.
If you are looking for a solution that has this functionality baked in, check out Conectara!

For the process to building this into an existing cloud-based solution, let’s begin!
Overview of the Solution
The solution consists of a web application that interacts with multiple services in AWS, as shown below:
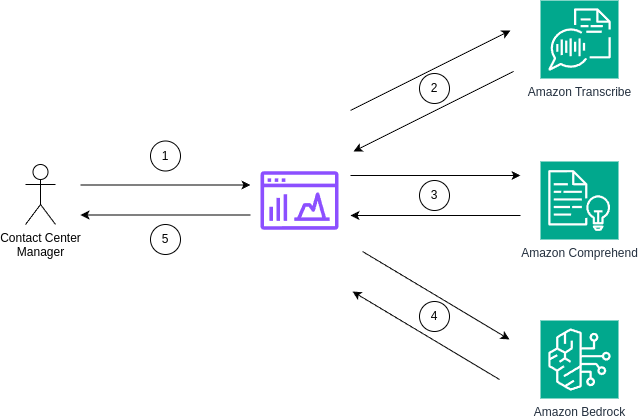
Here’s the order of operations:
- The contact center manager selects the desired call recording.
- Amazon Transcribe processes the recording to generate the call’s transcript.
- Amazon Comprehend analyzes the transcription to extract insights and sentiment.
- Amazon Bedrock summarizes the call transcript and also checks it against a set of legal and regulatory policies
- Chosen relevant information is displayed on the application’s dashboard for review.
Transcribing Call Recordings using Amazon Transcribe
The first step is to get call recording transcripts from Amazon Transcribe. To do so you need to call the StartTranscriptionJob API and pass the parameters of the job. Let’s start by defining these parameters.
In the context of contact centers, you need to set:
- The route to the call recording in an S3 bucket.
- If managing calls in multiple languages, enable Transcribe to identify the language of the call.
- Prepare Transcribe to identify and separate speakers (customer and agent).
- A name for the transcription job. This should be something meaningful for your business that allows you to identify the call.
- The output S3 bucket and route for the transcription file
The above is defined in the getTranscribeCallParams function below:
const getTranscribeCallParams = (filename: string) => {
// generate a transcription name
const jobName = getTranscriptionJobName(filename);
// set parameters
const transcribeParams = {
Media: {
// 1. the route of the call recording in S3
MediaFileUri: `s3://${BUCKET_NAME}/${filename}`,
},
// 2. Identify the language of the call
IdentifyLanguage: true,
// 3. Identify and separate speakers
Settings: {
ShowSpeakerLabels: true,
MaxSpeakerLabels: 2,
ChannelIdentification: false,
},
// 4. Set the name for the transcription job
TranscriptionJobName: jobName,
// 5. The output S3 bucket and route for the transcription file
OutputBucketName: `${BUCKET_NAME}`,
OutputKey: 'analytics/'+ jobName+'.json',
};
return transcribeParams;
}Next, you call the .startTranscriptionJob function and wait for Transcribe to perform the job.
const transcribeNewCall = async(filename: string) => {
try {
// get parameters
const transcribeParams = getTranscribeCallParams(filename);
// start transcription job
await transcribeService.startTranscriptionJob(transcribeParams).promise();
const jobName = getTranscriptionJobName(filename);
// wait for the job to finish
const transcript_response = await checkTranscriptionJobStatus(jobName);
return transcript_response;
} catch(err) {
throw new Error("Error While Transcribing New Call Audio");
}
}The checkTranscriptionJobStatus can be implemented as a recursive function that polls Amazon Transcribe for the completion of the job, using the results from calling the GetTranscriptionJob API. If the job’s status is COMPLETED, the function can download the transcript file from the S3 bucket specified as the output, as follows:
const checkTranscriptionJobStatus = async (jobName: string) => {
// call getTranscriptionJob function
const result = await transcribeService
.getTranscriptionJob({ TranscriptionJobName: jobName })
.promise();
// check the status of the job
if (result?.TranscriptionJob?.TranscriptionJobStatus === "COMPLETED") {
// if completed, get the transcript file from S3
const response = await fetchTranscriptFromS3(jobName);
return response;
} else {
// otherwise, check every 5 seconds until the job is completed
return new Promise((resolve) =>
setTimeout(
async () => resolve(await checkTranscriptionJobStatus(jobName)),
5000
)
); // Check every 5 seconds
}
};Extracting Sentiments and Insights using Amazon Comprehend
To build an insightful post-call analysis page, we leverage Amazon Comprehend’s NLP capabilities. This allows us to extract key phrases and sentiments from call transcriptions using AWS’s machine learning service.
Let’s start by creating a function that takes a call transcript (transcript) as input, along with an optional code variable in case you need to support multiple languages. Its goal is to identify and return the key phrases from the given transcript. Here’s a quick rundown:
- It initializes a new AWS Comprehend client.
- It calls the detectKeyPhrases method on the Comprehend client, passing in the transcript and the appropriate language code (en for English or es for Spanish).
- If successful, it returns an array of key phrases. If not, it logs the error message and returns an empty array.
export const getInsightsFromComprehend = async (
transcript: string,
code = 'en'
) => {
try {
// Initialize a new AWS Comprehend client
const comprehend = new AWS.Comprehend();
// Detect key phrases in the given transcript using the appropriate language code
const response = await comprehend
.detectKeyPhrases({
Text: transcript,
LanguageCode: code,
})
.promise();
// Return an array of detected key phrases
return response?.KeyPhrases;
} catch (error) {
console.error("Error getting insights from comprehend");
// In case of error, return an empty array
return [];
}
};Next, we need to get sentiments. Again, let’s write a function that takes the transcription as input and aims to extract sentiments from each audio segment in the transcript. Here’s how it works:
- It initializes a new AWS Comprehend client.
- It extracts the transcript text from the input response.
- It chunks the extracted text into arrays of size 25 (as per Amazon Comprehend’s batchDetectSentiment method limit).
- It maps over each chunk and sends an API request to detect sentiments, returning a promise for each request.
- Once all promises are fulfilled, it reduces the aggregated response into a single array containing all detected sentiments.
- If successful, it returns the aggregated sentiment results. If not, it logs the error message and returns an empty array.
export const getTranscriptSentiments = async (transcribe_response: any) => {
try {
// Initialize a new AWS Comprehend client
const comprehend = new AWS.Comprehend();
// Extract transcript text from input response
const text: string[] = transcribe_response?.results?.audio_segments?.map(
(item: any) => item?.transcript as string
);
// Chunk extracted text into arrays of size 25
const textSegments: string[][] = chunk(text, 25); // max array size for batchDetectSentiment is 25
// Map over each chunk and send API requests to detect sentiments
const responsePromises = textSegments.map((segment) =>
comprehend
.batchDetectSentiment({ TextList: segment, LanguageCode: "en" })
.promise()
);
// Once all promises are fulfilled, reduce aggregated response into a single array containing all detected sentiments
const response: AWS.Comprehend.BatchDetectSentimentResponse[] =
await Promise.all(responsePromises);
const aggregatedResponse = response.reduce((acm, item) => {
acm.push(...item?.ResultList);
return acm;
}, [] as AWS.Comprehend.ListOfDetectSentimentResult);
// Return aggregated sentiment results
return aggregatedResponse;
} catch (error) {
console.error("Error getting sentiments from comprehend");
// In case of error, return an empty array
return [];
}
};Retrieving Call Summary and Compliance Reports from Amazon Bedrock
To enhance post-call analysis capabilities, we integrate Amazon Bedrock for generating a call summary and creating a compliance report. Bedrock enables us to leverage Large Language Models (LLM), like Llama 3.1 or Anthropic Claude, for these tasks. Let’s understand how it retrieves this information.
First, let’s focus on getting a call summary. Start by improving the transcript so it clearly identifies the speakers. To do so, you perform an array reduction over the transcription results’ audio_segments property, and accumulate the transcript based on its items.
For each one, check the value of the speaker_label property and assign a role (Agent or Customer) as appropriate. Then, concatenate the accumulated transcript, the speaker label, the transcript text and add a new line, as shown below.
const generateTranscriptWithSpeakerLabels = (transcript_response: any) => {
// use the reduce function on the audio_segments property
const transcript = transcript_response?.results?.audio_segments.reduce(
(acm: any, item: any) => {
// assign a role based on the speaker_label property
const speakerLabel =
item.speaker_label === "spk_0" ? "Agent:" : "Customer: ";
// concatenate the result
return acm + speakerLabel + item.transcript + "\n";
},
[""]
);
return transcript;
};Next, write a function that generates a concise summary of the call transcript using Amazon Bedrock. Here’s what happens under the hood:
- It first processes the transcript, labeling speaker turns for better context, and adding an appropriate prompt for the model. Make sure to write a prompt that fits your needs.
- Set up the parameters for the LLM in Amazon Bedrock. Adapt this to your preferred values.
- In the example, the prompt is sent as a request to the Llama 3 model, which generates a summary based on the provided transcript.
export const getTranscriptSummary = async (
transcribe_response
) => {
// ... (transcript processing and prompt creation)
// set up params for bedrock
const bedrockParams = {
body: JSON.stringify({
prompt,
top_p: 0.9,
temperature: 0.5,
max_gen_len: 512
}),
contentType: "application/json",
modelId: "meta.llama3-70b-instruct-v1:0"
};
const bedrock = new AWS.BedrockRuntime();
try {
// send the request to Bedrock
const bedrockResponse = await bedrock
.invokeModel(bedrockParams)
.promise();
return JSON.parse(bedrockResponse.body.toString("utf-8")).generation;
} catch (error) {
console.log("Error generating transcript summary");
}
};Now, to get Amazon Bedrock analyze the call transcript against a set of legal and regulatory policies, you need to build an appropriate prompt that includes such policies.
Be sure to create one based on the needs of your Contact Center! For instance, take a snippet of the one we used in our example:
# Prompt
You are a robot that only outputs JSON.
Your role is to receive a call transcript of an internet service provider company between a customer and an agent and generate a call compliance report for the following:
1- Resolution Rate
2- Call Quality Score
3- Customer Satisfaction (CSAT)
4- Legal and Regulatory Compliance
Given the following information about the company's legal and regulatory policies in US:
*LEGAL AND REGULATORY POLICY STARTS*
Confidentiality:
Do not disclose personal information of customers to unauthorized parties.
Only share customer information with verified individuals and departments.
Data Protection:
Ensure all customer data is stored securely.
Use encryption for transmitting sensitive information.
Follow company protocols for handling data breaches
// prompt continues...For more complex scenarios, you can leverage a Retrieval-Augmented Generation (RAG) approach where you can provide compliance documents as additional context to the prompt.
Another recommended practice is to ask the model to return the report in a machine-friendly model, like JSON, so that you can process it using code.
Then you can reuse the same logic as the previous function, with the following differences:
- The function sends a request to the Llama 3 model, asking it to analyze the transcript against the provided policy.
- The model generates a JSON output containing scores and descriptions for each compliance category (i.e. resolution_rate, call_quality_score, csat, legal_regulatory_compliance), so the function tries to find a JSON object within the generated text by searching for { and } characters.
- If it finds one, it parses the extracted string as JSON and returns the resulting object.
- If no JSON object is found or an error occurs during parsing, it logs an error message.
Here’s how the function is structured:
export const getComplianceReport = async (
transcribe_response,
policies
) => {
// ... (request preparation)
try {
// send a request to Bedrock with an appropriate prompt
const bedrockResponse = await bedrock
.invokeModel(bedrockParams)
.promise();
// get the raw response
rawString = JSON
.parse(bedrockResponse.body.toString("utf-8"))
.generation;
// find a JSON object within the generated text
const jsonMatch = rawString.substring(
rawString.indexOf("{"),
rawString.lastIndexOf("}") + 1
);
if (jsonMatch) {
// if found, parse the response as JSON
const jsonObject = JSON.parse(jsonMatch);
return jsonObject;
} else {
// if not, show an error message
console.log("error while parsing json bedrock");
}
} catch (error) {
console.log("Error generating compliance report");
}
};Bringing it All Together in a Dashboard
Now it’s time to build the actual dashboard that fetches and displays insights from Amazon Transcribe, Amazon Comprehend, and Amazon Bedrock. This app will be the brains of your post-call analysis page, providing valuable insights into customer interactions.
Let’s start by creating a REST API on top of the functions we just built. The main function here is the GET method in our API route.
Here’s what our GET method does:
export async function GET(_: any, { params }: Params ) {
const { filename } = params;
try {
// Fetch transcription data from Amazon Transcribe.
const transcribe_response = await getTranscriptionFromTranscribe(filename);
// Check the language of the transcription.
const code = transcribe_response?.results?.language_code;
// Fetch compliance data from Bedrock.
const compliance = await getBedRockComplianceReports(transcribe_response, code);
// Fetch sentiments from Comprehend.
const sentiments = await getTranscriptSentiments(transcribe_response);
// Fetch insights from Comprehend.
const insights = await getInsightsFromComprehend(transcribe_response?.results?.transcripts[0]?.transcript);
// Fetch summary from Bedrock.
const summary = await getTranscriptSummary(transcribe_response, code);
return NextResponse.json({ transcribe_response, insights, compliance, sentiments, summary }, { status: 200 });
} catch(error) {
if (error instanceof Error) {
return NextResponse.json({ error: error.message }, { status: 400 });
}
return NextResponse.json({ error: "Unexpected Error" }, { status: 500 });
}
}In our frontend, we’ve set up an async function getData that fetches data from our backend API using the call audio file name as a parameter. This function is used in our main component, CallCompliance, which displays different sections of insights based on the fetched data.
Here’s what our getData function does:
async function getData(call_audio: string) {
const url = process.env.APP_URL || 'http://localhost:3000';
try {
const res = await fetch(url + `/api/transcribe/${call_audio}`, {
next: { revalidate: 3 }, // Revalidate every 3 seconds
});
if (!res.ok) {
return "error"
}
return res.json()
} catch (error) {
console.error("Error fetching data:", error);
throw error;
}
}In our CallCompliance component, we use getData to fetch the insights and display them using separate components for each type of insight:
<TranscribeComponent />: Displays the transcription of the call.<Compliance />: Displays compliance information.<KeyPhrases />:Displays key phrases derived from Comprehend’s analysis.<CallSummary />:Displays the call summary.
Once again, be sure your application implements each of these components according to the needs of your Contact Center.
export default async function CallCompliance({params}: Props) {
const { transcribe_response, compliance, insights, sentiments, summary } = await getData(params.call_audio);
// If there's no transcription data, display a 'File Not Found' message.
if(!transcribe_response) {
return (
<main>
<FileNotFound />
</main>
)
}
return (
<main className="flex flex-col md:flex-row m-8">
{/* Left section */}
<section className="w-full md:w-1/2 pr-4">
<Compliance compliance={compliance} />
<KeyPhrases key_phrases={insights ?? []} />
<CallSummary summary={summary} />
</section>
{/* Right section */}
<section className="w-full md:w-1/2 mt-8 md:mt-0 md:pl-4">
<TranscribeComponent
transcription={transcribe_response?.results?.audio_segments}
sentiments={sentiments}
/>
</section>
</main>
);
}Dashboard Demo!
Transforming Customer Interactions with AI-Powered Analysis
By harnessing the power of the Amazon Transcribe, Amazon Comprehend, and Amazon Bedrock services, we’ve built an customizable solution that provides valuable insights into customer interactions within contact centers and an AWS-powered transcription analysis dashboard using Next.js and TypeScript
As members of the Amazon Partner Network with our services available on the APN Marketplace, WebRTC.ventures has met stringent criteria for expertise, experience, and customer success. Our partnership with AWS means we are uniquely positioned to help you integrate advanced cloud-based solutions.
🚀 Ready to Elevate your Contact Center with AI-driven insights? Our team at WebRTC.ventures can help you implement a custom post-call analysis solution tailored to your business needs. Contact us today!
Interested in a tool that already implements these features? Conectara, our cloud-based Contact Center solution, is built upon Amazon Connect which leverages advanced AI features out-of-the-box. Visit https://conectara.ventures/ to learn more.










