
Last month I attended a remarkable WebRTC conference, JanusCon, which WebRTC.ventures also sponsored. I was fortunate as well to present a talk on integrating WebRTC with Large Action Models (LAMs). While “Large Action Models” is not yet an industry-wide term, it is generating interest from AI startups like Rabbit and browserbase, and is worthy of consideration from a WebRTC perspective.
LAMs (Large Action Models) are a subset of Large Multimodal Models (LMMs) that can perform actions. Similar to Large Language Models (LLMs), LAMs combine symbolic reasoning with neural networks and are trained using statistical relationships derived from vast amounts of text. However, LAMs extend this capability by translating their interactions into concrete actions, such as UI actions like clicking or typing, through the use of an agent.

Today, I expand on the piece of my talk where I explore the potential of WebRTC applications as an interface for using Large Action Models, including opportunities, challenges and use cases.
You can also:
My first contact with LAMs
Our team at WebRTC.ventures has been doing a lot of work lately involving AI in general, and LLMs, in particular. (In fact, we’re offering free AI Assessments to help businesses harness the combined power of WebRTC and AI!) However, the concept of LAMs is fairly new. I was excited to learn more and share that knowledge with the other conference participants.
My interest in LAMs had piqued after watching a presentation at CES 2024. The presentation showcased the Rabbit R1, a compact, smartphone-like device designed to interact with Large Language Models. What intrigued me was the use of LAMs to enable users to request complex operations, such as booking a hotel with specific characteristics or interacting with apps through voice commands.
How do LAMs work?
LAMs utilize Large Multimodal Models (LMMs), which can process and understand inputs from multiple modalities, such as images and text. They operate by:
- Understanding Elements: The model recognizes different elements on a webpage or app interface, like buttons, text boxes, and links. It sees a button and knows it’s a button.
- Interpreting Actions: The model understands what actions can be performed on these elements. It knows that buttons can be clicked, text boxes can be filled, and links can be followed.
- Making Decisions: Based on the context (what’s on the screen and what the user wants to do), the model decides what action to take. For example, if the user wants to book a hotel room, the model might click on the “Book Now” button. This is generally done out of the model by an agent app.
Below, you can see the high-level process for “finding ABC blog post” using a LAM for browsers. First, we use a tool to interact with the browser, open a specific website. Then, through image analysis, the LAM extracts information about the website and HTML elements. The LLM then returns the recommended next action.
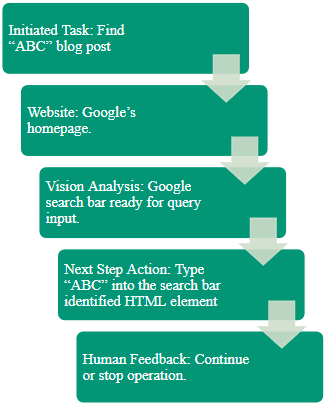
Any popular LLM, such as GPT-4o, can be used. But you will need some logic that transforms responses to actions, as well as an agent to perform the actions. For browser apps, such an agent can be Webdriver.io, Playwright or Puppeteer. Additionally, WebRTC can be used to provide visual feedback to the user while the agent is performing the actions.
If you’re interested in open-source projects, one notable example is OSU-NLP-Group/SeeAct: [ICML’24]. SeeAct is a system designed for generalist web agents that autonomously perform tasks on any website, emphasizing large multimodal models (LMMs) like GPT-4V(ision).
Opportunities Provided by LAMs
Among the opportunities provided by leveraging the capabilities of Large Action Models are:
- Enhanced User Experience and Efficiency: LAMs can significantly improve user experience by automating complex tasks and providing real-time, efficient solutions. This can lead to higher user satisfaction and engagement. For example, during a live video consultation session, an LAM could automatically fill out forms, schedule follow-up appointments, and provide documentation, all while the consultation is ongoing.
- Competitive Advantage Differentiation: Early adoption and successful implementation of LAMs can provide a competitive edge. Businesses that harness this technology can offer unique services and solutions, setting themselves apart in the market.
LAM Use Cases
Some uses for LAMs include:
- Travel Preparation: This could include searching email and calendars for flight information, checking in into the flight, and booking a ride to the airport (cross-checking ride-sharing apps).
- Customer Service: In customer service scenarios, a bot can assist users or agents in performing actions. The virtual agent could handle a wide range of tasks such as managing cloud services, updating account information, generating video documentation, or troubleshooting issues. This not only reduces the workload on humans, but provides faster results.

- Automated Smart Testing: This could involve the LAM interacting with apps and, for example, filling out web forms with various inputs to test validation rules, error messages, and submission processes.

And many more!
LAM Challenges
Not everything is always easy. Here are some challenges that could be encountered with using LAMs:
- Latency: Implementing LAMs into WebRTC applications involves complex multi-step operations that lead to high latency, making real-time execution difficult. Performing some of these longer actions asynchronously is the only viable approach for now.
While advancements in technology may reduce latency in the near future, today we can focus on single operations like suggestions, summaries, translations or interacting with a bot/agent, which are feasible in almost real-time.
- Accuracy: Implementing LAMs requires sophisticated AI models capable of understanding and executing a wide range of actions accurately. Ensuring the reliability and precision of these models is challenging. A highly specific focus for each implementation is essential to achieve high accuracy rates.
Are You Ready for the Next Generation Real Time Application using LLMs?
Are you ready to combine the power of WebRTC and AI for richer, more immersive, and secure communication experiences? Our team of experts can help you capitalize on the enormous opportunities. Learn more at ai.webrtc.ventures and request a free AI assessment!










