
In A Serverless Approach to Post-Call Analysis Using AWS Lambda, Amazon Transcribe, and Amazon Bedrock, we saw the benefits of leveraging a serverless model for implementing AI-based post-call analysis in contact center solutions. We highlighted how building such a pipeline to evaluate service and sales calls avoids the compilations inherent in provisioning the underlying infrastructure of an AI model and avoids paying for unused resources. Instead, your technical team can focus on the application itself, and your management team can have powerful data in their hands to evaluate and improve customer service and sales activities.
In this post, we will get a bit more technical. We will run through a practical example of how to implement such a feature using the three AWS services we introduced earlier: AWS Lambda for running code without thinking about servers or clusters, Amazon Bedrock for building and scaling Generative AI applications with foundation models, and Amazon Transcribe as said Generative AI application – which we will use for call transcripts and conversation insights.

Prerequisites
This post assumes that you already have a working WebRTC application with recordings enabled. (We can help you to build one.) and that you have an AWS account where you can upload such recordings. You also need to have your application authenticated with your AWS account.
Architecture Overview
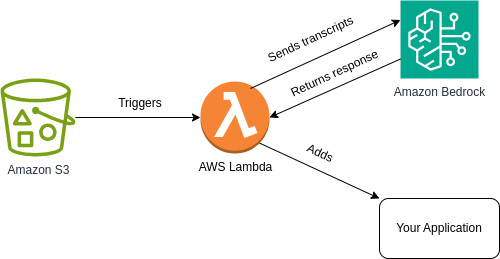
Our serverless post-call analysis pipeline begins after your application uploads a call recording file to S3. This triggers an AWS Lambda function that initiates a transcription job in Amazon Transcribe specifying the input audio and an output location for the transcriptions.

When a transcript is available in the specified output location, a new AWS Lambda is triggered. This time it is to process the transcription file and create a prompt that is later sent in a request to Amazon Bedrock. Such a prompt instructs one of the foundational models available in the service to generate the insights you need and return these as a response.
You can then store such a response in a file and upload it to a new S3 bucket, or directly add them to your application through a custom REST API endpoint or whichever other method you choose.
Preparation Steps
Before getting into the actual post-call analysis pipeline, there are a few steps we need to perform:
- Enable your application to upload call recordings to S3.
- Create the required AWS Lambda functions.
- Create the triggers that initiate those functions.
Step 1: Uploading Call Recordings to S3
First, you need to create an S3 bucket. Then, use one of the many SDKs available to give your application the ability to upload files to it. For instance, uploading a file to S3 using boto3 can be done using the code below.
import boto3
s3_client = boto3.client('s3')
try:
with open('call_recording.mp3','rb') as f:
s3_client.upload_fileobj(f, 'my_bucket', 'call_recording.mp3')
except ClientError as e:
logging.error(e)Step Two: Creating Lambda Functions
Next, you need to create the Lambda functions for your pipeline. You need two functions: one for initiating the transcription job, and another for interacting with Amazon Bedrock. Follow the instructions in the “Getting started with Lambda” page from AWS documentation to learn how to create such functions.
Your Lambda functions will also need permissions to interact with other AWS resources. Check the “Lambda resource access permissions” page in the AWS documentation to learn more about how these are assigned. Initially, your functions will need read and write access to the S3 bucket, along with permissions to initiate transcription jobs in Amazon Transcribe, and invoking a model in Amazon Bedrock. Make sure to adjust this set of permissions to your own needs.
If you need more advanced features such as testing functions locally and collaborating with other team members, you can leverage a framework like the Serverless Framework or AWS Serverless Application Model to build and deploy such functions.
Step Three: Creating Triggers for Lambda Functions
After creating the Lambda functions, you want to trigger these automatically when a recording is uploaded to S3. To do so, follow the steps outlined in the “Tutorial: Using an Amazon S3 trigger to invoke a Lambda function” page from AWS documentation.
Transcribing Call Recordings with Amazon Transcribe
The first step in the pipeline is converting the call recording into text. To do so, you must create a transcription job in Amazon Transcribe.
Assuming that your call recording is called “20240311-LyndaCarter-001.mp4” and was uploaded to a bucket called “CallRecordings” under the “recordings/” prefix, you can add the code below into your function to start a unique named job into Amazon Transcribe that transcribes such a file, and puts the resulting transcripts in the same bucket but under the “transcripts/” prefix.
import uuid
import boto3
transcribe_client = boto3.client('transcribe')
bucket_name = 'CallRecordings'
recording_language = 'en-US'
input_file = '20240311-LyndaCarter-001'
input_prefix = 'recordings'
input_media = 'mp3'
output_file = f'{input_file}-transcript.json'
output_prefix = 'transcripts'
transcribe_client.start_transcription_job(
TranscriptionJobName='job-' + str(uuid.uuid4()),
Media={
'MediaFileUri': f's3://{bucket_name}/{input_prefix}/{input_file}.{input_media}'
},
MediaFormat=input_media,
LanguageCode=recording_language,
OutputBucketName=bucket_name,
OutputKey=f'{output_prefix}/{output_file}'
)Get Call Insights from Amazon Bedrock
When a transcript file is available and has been uploaded to the S3 bucket, another Lambda function is triggered. This function reads the transcripts and then uses these to create a prompt that is sent to Amazon Bedrock in order to get insights from them.
Assuming that the call transcript is available in the transcript variable, you can use the code below in your function to get a summary of the call from Amazon Bedrock. In the example we use v1 of Amazon Titan Express model, but you can check all the available ones in Bedrock’s front page.
import boto3
import json
bedrock_runtime = boto3.client('bedrock-runtime')
prompt = f'''Provide a summary of the call transcript surrounded by triple backticks.
```
{transcript}
```'''
kwargs = {
"modelId": "amazon.titan-text-express-v1",
"contentType": "application/json",
"accept": "application/json",
"body": json.dumps(
{
"inputText": prompt
}
)
}
response = bedrock_runtime.invoke_model(**kwargs)
summary = (
json.loads(response.get('body').read())
.get('results')[0]
.get('outputText')
) Now you can send the summary back to your application. Assuming that your application has a /call_summary endpoint that accepts a POST request with the summary, you can use the following code to do so.
import requests
url = 'https://your-application-url/api/call_summary'
myobj = {'summary': summary}
x = requests.post(url, json = myobj)Post-Call Analysis for Your Application, No (Visible) Servers Involved!
Implementing post-call analysis in your contact center solution doesn’t need to be a daunting task nor should it break the bank.
By leveraging AWS Lambda, you can enable an event-driven approach where the pipeline is only executed when it needs to, and charged only for what it uses.
Amazon Transcribe allows you to transcribe call recordings that are uploaded to an S3 bucket and store transcripts in the same or a different bucket. Once you have the transcript, you can build an appropriate prompt that can be sent to Amazon Bedrock in order to get the call insights you need for your application, such as a summary or any kind of inference from it.
If you’re struggling with implementing post-call analysis – or any other LLM-based feature – in your real-time communication application, or you’re building one from scratch, our team has you covered! Contact us today to take your contact center solution to the next level. Let’s make it live!









