
WebRTC applications are often initially built to handle a minimal number of users. Later, as an app proves its usefulness in the marketplace and becomes successful, it is necessary to increase the number of WebRTC connections it can handle. This type of application scaling is an important and regular part of our work here at WebRTC.ventures. Often we can refactor the existing application. Other times, it becomes necessary to apply a new architecture entirely.
In this post, we are going to talk anonymously about an application where we did not do the initial development work. We were brought in later to help the client scale the application to serve a larger user base. Many of these scaling considerations would work in any application. Others are specific to WebRTC and video messaging.
To Rebuild or Not To Rebuild?
This application was a legacy system based on Kurento, an open source WebRTC media server. The first question was could it be scaled or should we rebuild from scratch? We went with refactoring the existing application. This led to a lot of other considerations and concerns. We will cover some of the main ones here, along with the solutions that our team put into place.
Infrastructure Upgrades
In this scenario, we upgraded infrastructure by providing a Kubernetes cluster. Kubernetes, also known as K8s, is an open-source system for automating deployment, scaling, and management of containerized applications. In the cluster, multiple instances of our services can run so if there is an increase in users, we can increase the number of instances in which services are running in the cluster. We can also free up some resources in order to handle a decrease in demand. Another benefit of this infrastructure upgrade is that in case of a service failure, we will have other instances of that service running.
While there are many benefits, there are of course also problems associated with upgrading your infrastructure. Let’s look at two and see how we solved them.
Communication Issues
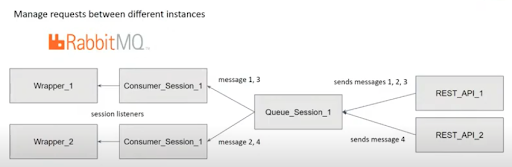
In this application, there are two main services: the REST API and the Wrapper. The REST API receives requests from the client and sends requests to the Wrapper. The Wrapper handles all of the Kurento-related logic. We have to be able to send messages from service to service, which we were already doing before the upgrade. But now we have multiple instances of the service, and we want requests only to be handled by a single instance of the service. We don’t want to process the same request twice (e.g., create the same connection twice).
We used RabbitMQ, an open-source message-broker software communication. RabbitMQ allows us to consume messages only once, even if there are multiple consumers of the same queue (one in each instance). Messages are load balanced, which allows us to distribute requests among all the instances that are consuming the queue. This decision was based on the client’s need to host the application internally. Had this not been the case, we could have considered commercial real-time messaging solutions for the queuing, such as PubNub.
With fanout exchange, we can also send a message to multiple queues. This allows us to send the same message to multiple user queues at once by binding the user queues to the session exchange. All the user queues will consume that message.
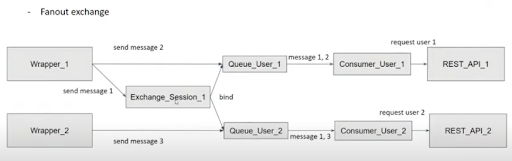
We use HTTP polling to receive the messages sent to a user. This means that a client sends a request to the REST API to read all the messages stored in its user queue. It will consume the messages sent to the user queue which are: the messages sent directly to the user queue and the ones sent to the session exchange that it is bound to. In the example above, for user 1 it will consume messages 1 and 2 and for user 2 it will consume messages 1 and 3.
Data Management Issues
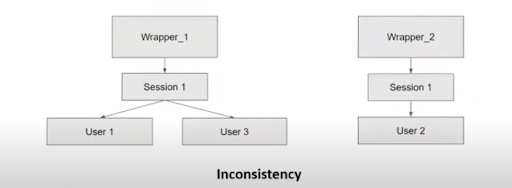
Data persistence is a very important concept. Previously, we had data stored in the service memory. This makes it vulnerable to service failure. Furthermore, since each instance of the service can process different requests of a session, without a database the instances would have different data in memory.
We decided to use MongoDB to store all of the data related to a session. MongoDB is a source-available cross-platform document-oriented database program. This way, we are able to process requests from all instances of the Wrapper and the data will be consistent, since we will be reading it from and writing on the mongo database.
Reactive streams
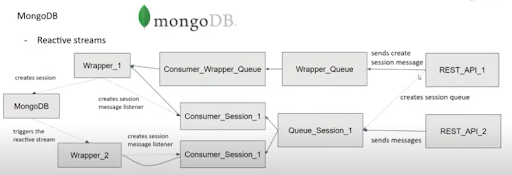
When we create a session, a message is sent from the client to the REST API. It will create the session queue and send the message to the Wrapper queue. But only a single instance will receive the session creation message. It will create a session message listener and then insert the new session to the mongo database.
The session message listener will handle different requests like: join, offer, ICE candidates… And besides storing the session data (media pipeline, users, connections…) in MongoDB it will also create the WebRTC endpoints, send answers, gather ICE candidates, send ICE candidates, connect endpoints, etc.
But this way, only a single instance will process requests. We also want other Wrapper instances to be able to process the requests for that session. So we need to create the session message listeners for all the Wrapper instances. To do this, we use reactive streams. We set a listener for inserts on the session collection. When a Wrapper instance consumes the create session message, it will create the session message listener and insert a new session into the mongo database. This will trigger the reactive stream, which is set for all Wrapper instances, and therefore create the session message listener for all of them. Now we have all Wrappers consuming from the session queue. Future requests for that session will go through the session queue.
Mongo custom conversions
We had an issue storing the data since there are some objects of our session that can’t be stored directly into the mongo database. These objects are the Kurento objects which are the media pipeline and WebRTC endpoints. To solve this, we used Mongo custom conversions for reading and writing from and to mongoDB. It maps the MongoDB documents into our Java objects and vice versa.
To store a session in MongoDB, we have to map the media pipeline into a string, which will be the media pipeline ID. To read the session back, we use that ID to retrieve the media pipeline object using some Kurento client methods. We get the Kurento server for that session, then get the pipelines of that Kurento server and finally find the one that matches our ID. The same happens with the WebRTC endpoints of a session.
Partial updates
We also faced an issue with data consistency when two Wrapper instances were modifying the same session at the same time. Both would be reading and writing the same session document from mongoDB, thus causing an overwrite of some of the data that one of the instances changed.
The solution was to use partial updates. That is, to modify only the data that is required to be modified instead of reading and writing the whole document. We used the updateOne method of the MongoCollection, which accepts a filter that matches the document you want to update and an update statement. In the update statement you can specify the changes that need to be applied using the update operators. We used set, push, pull and the array identifier. This way we can set a field value, push an element into an array or pull one element from an array.
How to Handle the Reconnection
During a call we can experience disconnections. There are two types of disconnections we are handling: when a Kurento Media Server (KMS) goes down or when a client disconnects due to connectivity issues.
If a Kurento Media Server (KMS) goes down, we need to reconnect all of the users that were in that session using a different KMS. When this happens all users get a disconnected event and a reconnect option will be displayed. They will be able to join again. When handling the new join requests of the session, we detect that there is no media pipeline for that session (since the server is down), so we check for KMS availability. First, we will try to reconnect the KMS that dropped and then select it if it is working back again. Else, we will select a different available KMS, the one with the lowest memory usage. Then we just create a new media pipeline for the session and save it in the mongoDB. All future session requests (like the rejoins) will use the new media pipeline to create the connections.
If a client drops, a ‘connection failed’ event will be triggered and the user will receive a notification about the disconnection issue. The client can try to reconnect to the session by sending a join request, which will start the join process again as if it was a new user connecting. But sometimes this can be too sensitive, since connections can be reestablished automatically even when they fail. To manage that we can add a timer or counter before attempting to reconnect.
Conclusion
When thinking about refactoring an application to make it scalable, there are many aspects to take into consideration. You will most likely want to set multiple instances of your services, which will require data storage and data consistency across all of them. In the case of a WebRTC application, you will also need to store some objects that need to be mapped (like the media pipeline and WebRTC endpoints in our case). You will also need to set up the communication between services and think about how to configure all the queues for your instances so that messages can be consumed by any instance of a service. These are only some of the considerations you will need to take into account when upgrading your application.
For more on the subject (and a demo):
If you need help scaling your WebRTC app, let our expert team be your guide. Fill out a contact form and let us know how we can help!









