There are many different ways to build your WebRTC application. You can use a CPaaS service like Vonage, Twilio or Agora. You can implement your own Peer-to-Peer application directly against the standard. Or, you can build on top of open source media servers like Jitsi and Janus.
If you choose to use open source media servers, the next thing to decide is whether you want to use an SFU or an MCU. What does that mean? We have a WebRTC Tip video embedded below to help you answer that question. Or, read on.
There’s no right or wrong answer when considering media servers. It all depends on your use case.
Media servers vs pure peer-to-peer
Before I explain the difference between an SFU and an MCU and why you might choose one over the other, let’s first review why you might use a media server instead of building a pure peer-to-peer WebRTC application.
The most common reason you will need a media server is: group calls. WebRTC doesn’t scale well to large conversations in a pure peer-to-peer architecture. The following image shows why.
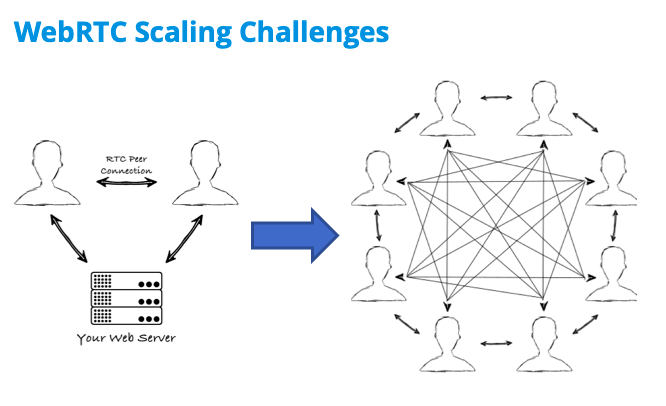
On the left, we show a simple peer-to-peer call. Two users are connected with each other via a signaling process (which you create as part of your app), and then an RTC Peer Connection is established. At this point, all data is exchanged between the peers directly, without using your server.
If you try to scale the same architecture to a group call, it gets much more complicated, as shown on the right side of the figure above. The signaling process on your web server still exists, but it’s been removed from the diagram, and now we are just showing how complex a mesh network of peer-to-peer connections between each party in the group call looks. Handling so many connections causes a lot of processing burden on each peer, so your group call will frequently fail.
To support group chats, as well as to include other features like call recording and transcription, most applications incorporate a media server to handle the traffic between the peers and scale better.
That leads us to a brief discussion of the two types of media servers: SFUs and MCUs.
MCUs – Multipoint Control Units
MCUs are also referred to as Multipoint Conferencing Units. Whichever way you spell it out, the basic functionality is shown in the following diagram.
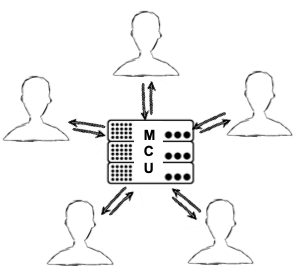
Each peer in the group call establishes a connection with the MCU server to send up its video and audio. The MCU, in turn, makes a composite video and audio stream containing all of the video/audio from each of the peers, and sends that back to everyone.
Regardless of the number of participants in the call, the MCU makes sure that each participant gets only one set of video and audio. This means the participants’ computers don’t have to do nearly as much work. The tradeoff is that the MCU is now doing that same work. So, as your calls and applications grow, you will need bigger servers in an MCU-based architecture than an SFU-based architecture. But, your participants can access the streams reliably and you won’t bog down their devices.
Media servers that implement MCU architectures include Kurento (which Twilio Video is based on), Frozen Mountain, and FreeSwitch.
SFUs – Selective Forwarding Units
A group call on an SFU looks different, as shown below.
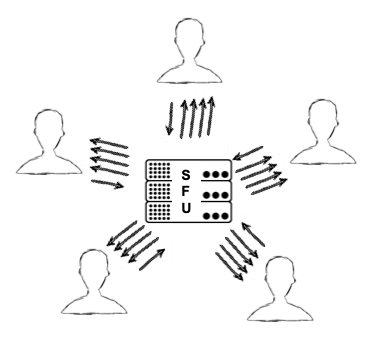
In this case, each participant still sends just one set of video and audio up to the SFU, like our MCU. However, the SFU doesn’t make any composite streams. Rather, it sends a different stream down for each user. In this example, 4 streams are received by each participant, since there are 5 people in the call.
The good thing about this is it’s still less work on each participant than a mesh peer-to-peer model. This is because each participant is only establishing one connection (to the SFU) instead of to all other participants to upload their own video/audio. But, it can be more bandwidth intensive than the MCU because the participants each receive multiple streams downloaded.
The nice thing for participants about receiving separate streams is that they can do whatever they want with them. They are not bound to layout or UI decisions of the MCU. If you have been in a conference call where the conferencing tool allowed you to choose a different layout (ie, which speaker’s video will be most prominent, or how you want to arrange the videos on the screen), then that was using an SFU.
Media servers which implement an SFU architecture include Jitsi and Janus.
Why choose an MCU?
- If you don’t mind unpredictable CPU costs, but need very predictable bandwidth costs
- If you want to interface with a telephony system or other external systems, an MCU is helpful since it will create composite video and/or audio streams which you can then send on to that external system.
- Some of the devices connected to your call have serious bandwidth constraints and so giving them a composite stream is helpful or controlling what codec they receive the video in is helpful
Why choose an SFU?
- To reduce the CPU load on your media server, which will allow you to scale your system better and at lower cost
- To allow participants to have different video layouts
- End to end encryption – Because an SFU doesn’t need to manipulate your video in the way that an MCU does, that means you could conceivably implement true end to end encryption where the media server doesn’t have the keys to decrypt your video and audio streams
Why not both?
There are actually scenarios where you might want to use both, which I describe towards the end of the WebRTC Tip video on SFUs and MCUs.
Are you interested in more WebRTC Tips like this? Make sure to follow us on YouTube and on Twitter, where we share the expertise that our team of experts have acquired from years of building live video applications. Contact us today to build yours!









